The Free AI Landscape in Legal Research Today
The phrase "free AI for legal research" covers a range of offerings that differ far more in risk profile than in price tag. A free tier of a general-purpose chatbot, a source-cited search engine, a document Q&A tool, and a purpose-built legal research platform each impose a different verification burden on the attorney who relies on the output. Treating them as interchangeable options — as many listicles do — ignores the professional responsibility obligations that attach to every research task a licensed attorney performs.
This guide organizes free AI legal research tools into four risk tiers, grounded in the most rigorous publicly available benchmark of legal AI hallucination rates: the Stanford RegLab study (Magesh et al., 2024). The framework is designed to help attorneys, paralegals, and law students match tool capability to the specific professional responsibility requirements of each research task — from rapid orientation on a novel legal question to citation verification for a court filing.
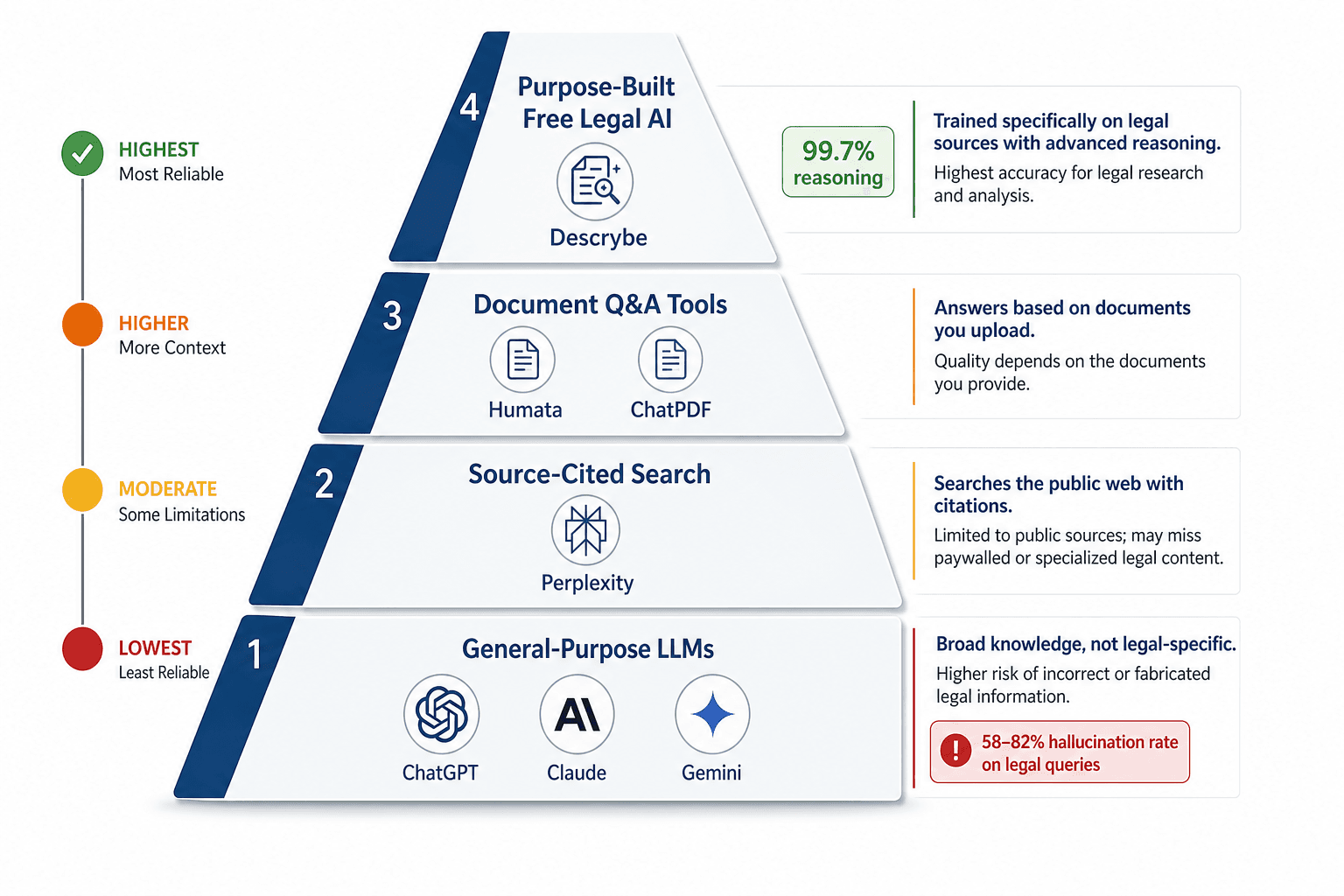
Risk Tier 1: General-Purpose LLMs (ChatGPT, Claude, Gemini)
The free tiers of ChatGPT, Claude, and Gemini are the most accessible entry points for legal professionals curious about AI-assisted research. They are also the highest-risk option for any task that requires accurate legal authority.
The Stanford RegLab study tested general-purpose chatbots on over 200 open-ended legal queries and found that they hallucinated between 58% and 82% of the time. Hallucinations took two forms: responses that were substantively incorrect (misstating the law) and responses that were misgrounded (citing sources that do not support the claim). For an attorney relying on a tool to surface case law or statutory interpretation, a hallucination rate above 50% means the output is more likely wrong than right.
Beyond accuracy, confidentiality is a material concern. Free tiers of general-purpose LLMs may use uploaded content for model training. The SpotDraft article notes that free tiers of these tools may use uploaded content for model training, and the Thomson Reuters analysis warns that public LLMs pose security risks because they are not trained on legal-specific datasets. An attorney who uploads a confidential brief or client communication to a free chatbot tier may be exposing privileged information.
Despite these limitations, general-purpose LLMs have a legitimate role in legal research: rapid orientation on unfamiliar topics, brainstorming search terms, and generating plain-language explanations of legal concepts. The key is to treat the output as a starting point for research, not as a source of authority. Every citation must be independently verified against primary law.
Risk Tier 2: Source-Cited Search Engines (Perplexity Free)
Perplexity's free tier occupies a distinct risk category because it returns answers with cited sources from live web content, rather than generating responses from a static training corpus. This design reduces — but does not eliminate — the verification burden.
The Spellbook analysis notes that Perplexity delivers cited, sourced answers from publicly available sources in real time. Venture law firm Gunderson Dettmer rolled out Perplexity Enterprise firmwide, with 80% of attorneys (including partners) reporting active use and over 35,000 queries per month. This adoption data suggests that even sophisticated law firms find value in source-cited search for certain tasks.
However, Perplexity's free tier has critical limitations for legal research:
- It cannot access Westlaw, LexisNexis, or Fastcase databases. The sources it cites are from the public web, which may include secondary sources, blog posts, or outdated material.
- Citation verification is still required. The tool may cite a source that does not actually support the claim it makes — a form of misgrounding similar to what the Stanford study documented in general LLMs.
- The free tier's data privacy posture is weaker than the enterprise version. The Spellbook article notes that Standard/Pro tiers may use data to train models unless manually opted out, while the Enterprise tier includes SOC 2 Type II certification and a zero data retention policy.
For rapid orientation — getting a quick overview of a legal topic, identifying key statutes or cases, or understanding a regulatory framework — Perplexity's free tier is arguably the best option among freely available tools. But it is not a substitute for primary-law research, and every citation it produces should be independently verified.
Risk Tier 3: Document Q&A Tools (Humata, ChatPDF)
Document Q&A tools like Humata and ChatPDF allow users to upload PDFs and ask questions about their content, with answers citing specific sections of the uploaded document. These tools are useful for low-risk contract interrogation, deposition summary review, and internal document analysis.
The SpotDraft article describes Humata AI as allowing PDF upload and Q&A with answers citing specific sections, with free tier limits on pages and uploads. ChatPDF provides simple PDF summaries and clause identification but lacks legal-specific training.
The limitations of this tier are significant for legal research:
- These tools are not trained on legal-specific datasets. They can identify clauses and summarize text, but they cannot interpret legal meaning, assess jurisdiction-specific applicability, or flag missing provisions.
- Upload limits on free tiers restrict the volume of documents that can be processed. A single complex contract or deposition transcript may exceed the free tier's page limit.
- Privacy concerns apply. Uploading a confidential contract or privileged communication to a free-tier document Q&A tool may expose sensitive information, depending on the vendor's data retention policy.
- They are not suitable for jurisdiction-specific legal research. A tool that can summarize a contract clause cannot tell you how a particular state's courts have interpreted that clause.
Document Q&A tools are best reserved for internal, non-court-facing tasks where the cost of an error is low — reviewing a routine vendor agreement, summarizing a deposition transcript for internal use, or extracting key dates from a set of contracts. They should not be used for any research task that will be presented to a court or relied upon for legal advice.
Risk Tier 4: Purpose-Built Free Legal AI (Descrybe, Google Scholar + Gemini)
Purpose-built free legal AI tools represent the lowest-risk category among free options because they are designed specifically for legal research tasks and operate on structured primary-law corpora rather than general web content.
Descrybe is the most capable free option in this category. According to its documentation, Descrybe provides a platform and a Claude legal engine built on a structured corpus of primary law. DescrybeLM scored 99.7% on reasoning quality across 200 Multistate Bar Exam questions, outperforming foundation models tested. The Descrybe Legal Engine gives Claude access to U.S. case law, statutes, regulations, citation lookup, quote verification, treatment checks, and source text.
The platform includes tools specifically designed for legal research verification: the Cytator (citing case treatments at case and legal-issue level), the Cytationator (checking every citation in a brief), and the Legal Issue Explorer (exploring over 6.5 million legal issues). These features directly address the verification burden that makes lower-tier tools risky for professional use.
A lower-cost alternative is the Google Scholar + Gemini workflow. Google Scholar provides free access to a substantial corpus of U.S. case law, and Gemini can be used to summarize or analyze cases found through Scholar. This workflow requires more manual effort — the attorney must find the cases, verify the citations, and use the LLM only for analysis of already-verified sources — but it keeps the attorney in control of the research process.
Descrybe's pricing starts at $25/month for the paid tier, which removes usage caps and adds additional features. The free tier is genuinely useful for structured primary-law research, but practitioners who need to verify citations in court filings or perform high-volume research should evaluate whether the paid tier's additional capabilities justify the cost.
What the Stanford RegLab Study Actually Found
The Stanford RegLab study (Magesh et al., 2024) remains the most important benchmark for understanding AI hallucination rates in legal contexts. Its findings directly undercut vendor claims of "hallucination-free" performance and provide a data-driven framework for evaluating tool risk.
The study tested three paid legal AI tools — Lexis+ AI, Westlaw AI-Assisted Research, and Ask Practical Law AI — alongside general-purpose chatbots, using over 200 open-ended legal queries. The results were sobering:
| Tool Category | Hallucination Rate | Source |
|---|---|---|
| General-purpose chatbots | 58% to 82% | Stanford HAI / RegLab (Magesh et al., 2024) |
| Lexis+ AI | More than 17% | Stanford HAI / RegLab (Magesh et al., 2024) |
| Ask Practical Law AI | More than 17% | Stanford HAI / RegLab (Magesh et al., 2024) |
| Westlaw AI-Assisted Research | More than 34% | Stanford HAI / RegLab (Magesh et al., 2024) |
The study found that hallucinations took two forms: responses that were incorrect (misstating the law) and responses that were misgrounded (citing sources that do not support the claim). Both forms are dangerous for legal professionals, but misgrounded hallucinations are particularly insidious because they appear to be supported by authority.
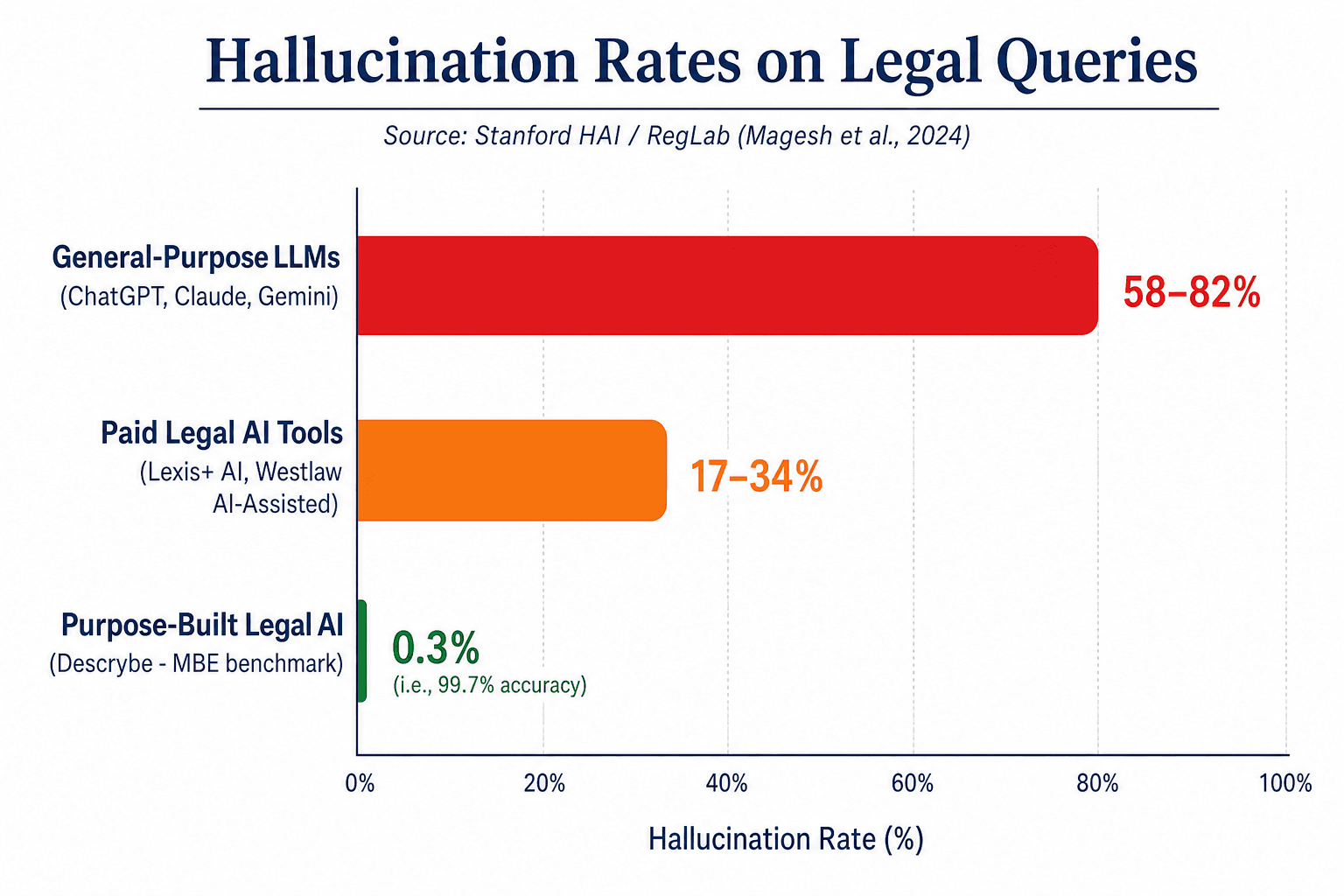
The implication for practitioners is clear: even the most expensive, purpose-built legal AI tools hallucinate at rates that would be unacceptable in a junior associate's work product. The difference between tiers is not whether hallucinations occur, but how frequently and how easily they can be detected. A tool that hallucinates 17% of the time places a lower verification burden on the attorney than one that hallucinates 82% of the time, but neither eliminates the need for independent verification.
Side-by-Side Comparison Table
The following table organizes all tools covered in this guide by risk tier, with key attributes for professional evaluation.
| Risk Tier | Tool | Free Tier Limits | Privacy Posture | Hallucination Risk | Best-Fit Use Case |
|---|---|---|---|---|---|
| 1 (Highest Risk) | ChatGPT Free, Claude Free, Gemini Free | Message caps, no custom GPTs, limited context window | May use data for training; no confidentiality guarantee | 58-82% on legal queries (Stanford HAI) | Rapid orientation, brainstorming, plain-language explanations |
| 2 (High Risk) | Perplexity Free | Limited queries per day, no file uploads | Standard/Pro may use data unless opted out; Enterprise has SOC 2 Type II | Lower than general LLMs, but misgrounding still documented | Rapid orientation with cited sources; not for primary-law research |
| 3 (Moderate Risk) | Humata Free, ChatPDF Free | Page and upload limits; varies by tool | Uploaded content may be used for training; check vendor policy | Not independently benchmarked; depends on underlying model | Low-risk contract Q&A, deposition summary, internal document analysis |
| 4 (Lowest Risk) | Descrybe Free | Usage caps on free tier; $25/month for unlimited | Structured primary-law corpus; check vendor privacy policy | 99.7% reasoning quality on MBE (Descrybe benchmark); not independently replicated | Structured primary-law research, citation verification, treatment checks |
| 4 (Lowest Risk) | Google Scholar + Gemini | Google Scholar free; Gemini free tier has message caps | Google Scholar: no upload; Gemini: standard privacy policy | Depends on how Gemini is used; lower risk if used only for analysis of verified sources | Low-cost alternative for case law research with manual verification |
Decision Framework: Which Free Tool for Which Task
Matching tool capability to task requirements is the core professional responsibility challenge when using free AI for legal research. The following decision matrix maps common research tasks to the appropriate tool tier, based on the verification burden each task can tolerate.
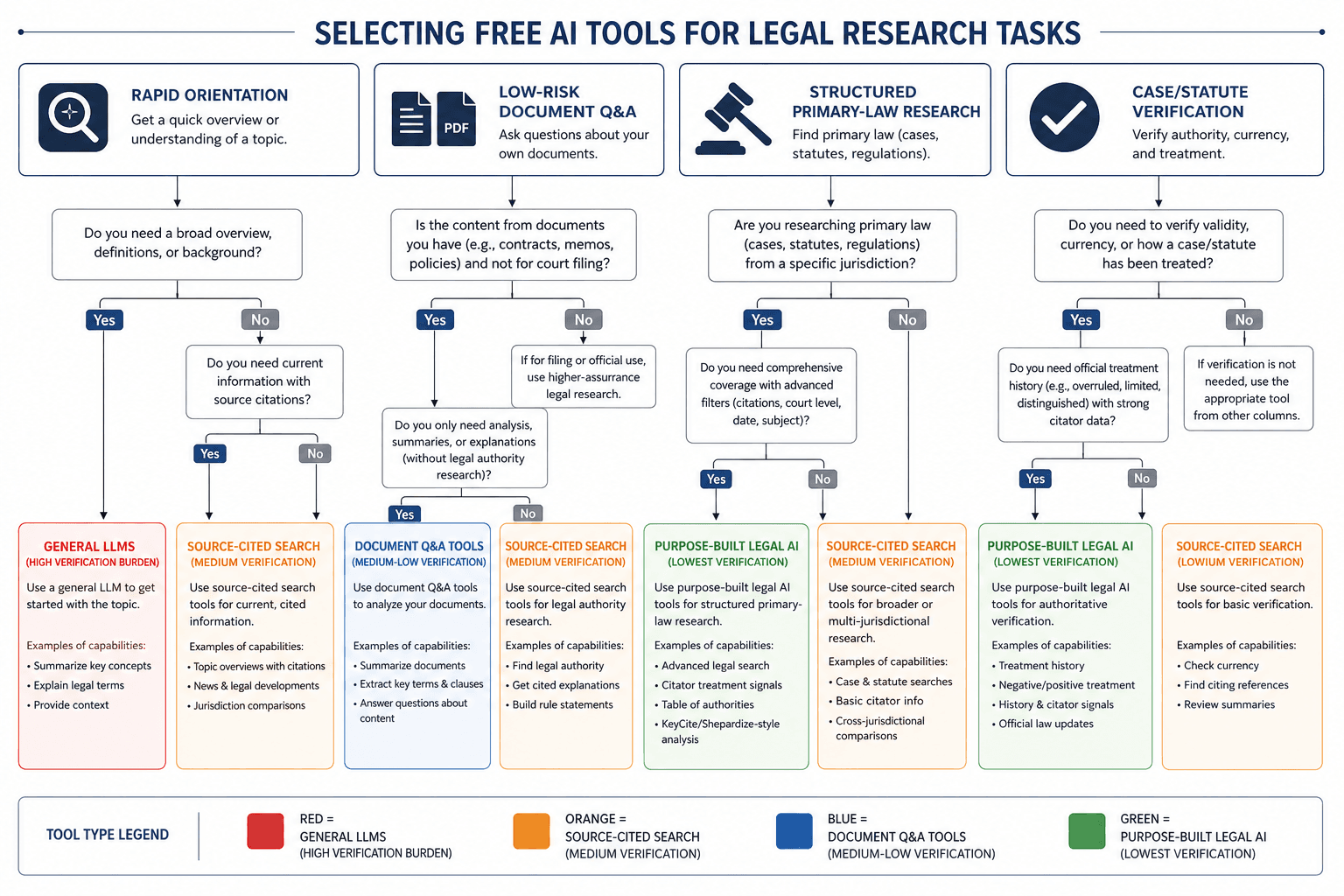
| Research Task | Recommended Tool Tier | Verification Burden | Professional Responsibility Note |
|---|---|---|---|
| Rapid orientation on a novel legal topic | Tier 2 (Perplexity Free) or Tier 1 (general LLMs) | High — verify all citations against primary law | Acceptable for initial exploration; never cite without verification |
| Summarizing a routine contract or deposition | Tier 3 (Humata, ChatPDF) | Moderate — verify key clauses and dates against original document | Acceptable for internal use; not for court-facing work |
| Finding case law on a specific legal issue | Tier 4 (Descrybe, Google Scholar + Gemini) | Low to moderate — verify citations and treatment | Descrybe's structured corpus reduces but does not eliminate verification need |
| Verifying citations in a brief or memo | Tier 4 (Descrybe Cytationator) | Low — tool checks each citation against primary law | Still requires attorney review; tool is an aid, not a substitute |
| Drafting a legal argument or analysis | None (use paid legal AI or traditional research) | Very high — free tools are not reliable for argument generation | Free tools should not be used for drafting court-facing arguments |
When Free Is Not Enough: Signals It's Time to Upgrade
Free AI tools have genuine utility in legal research, but every practitioner will eventually encounter tasks that exceed their capabilities. The following signals indicate that free tools are no longer sufficient and that a paid legal AI tool or traditional research methods should be used.
- You need jurisdiction-specific accuracy. Free tools that draw from the public web cannot reliably distinguish between federal and state law, or between different state court interpretations. If your research requires knowing how the Ninth Circuit interprets a statute versus the Fifth Circuit, free tools are not adequate.
- You are spending more time verifying citations than doing research. If the verification burden of a free tool exceeds the time it saves, the tool is no longer serving its purpose. The Stanford study found that even paid legal AI tools hallucinate 17-34% of the time; free tools with higher hallucination rates require proportionally more verification.
- You need to upload confidential or privileged documents. Free tiers of general-purpose LLMs and document Q&A tools may use uploaded content for model training. If your research involves client confidences, attorney work product, or privileged communications, you need a tool with a documented zero data retention policy and appropriate security certifications.
- Your research will be presented to a court. Any research that forms the basis of a filing, motion, or oral argument should be conducted using tools that provide verifiable, source-cited access to primary law. Free tools — even purpose-built ones — should be used only as a supplement to traditional research methods for court-facing work.
- You have hit the free tier's usage caps. If you are regularly exceeding the message limits, upload caps, or query restrictions of a free tool, the cost of the paid tier may be justified by the time savings. Descrybe's paid tier starts at $25/month; Perplexity Pro is $20/month. Compare these costs against the billable hours spent on manual research.
Comments
Join the discussion with an anonymous comment.