What Is RAG? A Plain-Language Definition with Technical Precision
Retrieval-Augmented Generation (RAG) is an AI architecture that combines a retrieval system with a large language model (LLM). Think of it as the difference between a closed-book exam and an open-book exam. A general-purpose LLM like ChatGPT relies entirely on its internal memory — the patterns it learned during training — to generate answers. When that memory is incomplete or outdated, the model guesses, and those guesses are what the legal profession has learned to call hallucinations.
A RAG system, by contrast, first retrieves relevant documents from a trusted, curated database — case law, statutes, regulations, or firm precedents — and then feeds those documents into the LLM as context before generating a response. The LLM does not rely on its memory; it reads the retrieved sources and answers based on what it finds there. This is why RAG is the architectural backbone of professional-grade legal AI tools: it enables the system to cite actual authorities and ground its output in verifiable text.
In legal practice, this distinction matters enormously. When a lawyer asks a general LLM "What is the Daubert standard for expert testimony in the Ninth Circuit?" the model may produce a plausible-sounding answer that mixes correct law with fabricated citations. A RAG-powered legal research tool, however, first searches a database like Westlaw or LexisNexis for the relevant Ninth Circuit opinions, retrieves the actual text of those opinions, and then generates an answer that cites the specific cases it found. The lawyer can click through to verify the source.
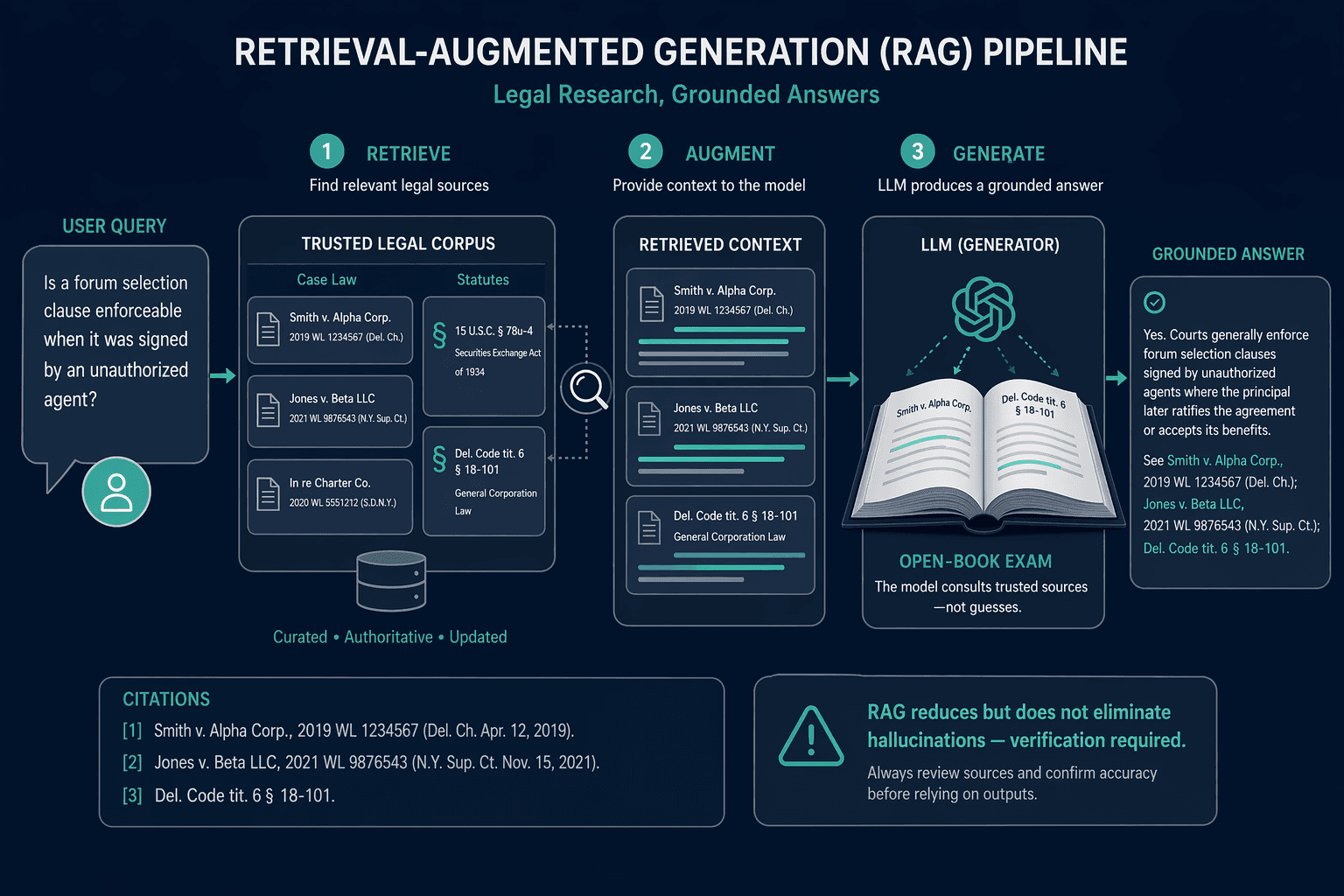
How RAG Works: The Retriever → Augmentation → Generator Pipeline
A RAG pipeline consists of three distinct stages. Understanding each stage is essential for evaluating legal AI tools, because the quality of the output depends on the quality of every link in the chain.
- 1. Retrieve. The system takes the user's query and searches a pre-indexed database of legal documents. This database may be a public corpus (e.g., a vendor's collection of case law and statutes) or a private corpus (e.g., a law firm's repository of briefs, contracts, and memoranda). The retrieval step uses techniques like vector similarity search to find the most relevant passages. The LegalBench-RAG benchmark, introduced in 2024, was specifically designed to evaluate this retrieval step, using a human-annotated dataset of 6,858 query-answer pairs over a corpus of over 79 million characters to measure how well retrieval systems find the right legal text.
- 2. Augment. The retrieved documents are inserted into the LLM's context window — the limited amount of text the model can process at once. The system constructs a prompt that includes both the user's question and the retrieved source material. This step is critical: if the retrieved documents are irrelevant, incomplete, or from the wrong jurisdiction, the LLM's answer will be flawed regardless of how powerful the underlying model is.
- 3. Generate. The LLM reads the augmented prompt and produces a response grounded in the retrieved sources. Because the model has the actual text of the relevant authorities in its context, it can quote, paraphrase, and cite those authorities rather than fabricating them from memory. The output is typically presented with inline citations that link back to the source documents.
As the Thomson Reuters blog on RAG in legal tech notes, "poor retrieval and/or bad context can be just as bad as or worse than relying on an LLM's internal memory." A RAG system is only as good as its retrieval step and the quality of the database it searches.
Why Law Is Uniquely Suited to RAG
Law is an unusually good fit for the RAG architecture because the profession's core work revolves around authoritative, citable sources. A lawyer does not invent the law; they find it, interpret it, and apply it. This reliance on a finite (though vast) corpus of primary and secondary sources — case law, statutes, regulations, administrative guidance, contracts — maps directly onto the retrieval step that RAG systems perform.
General knowledge domains do not have this structure. If you ask a RAG system "What is the best way to train for a marathon?" there is no authoritative corpus to retrieve from — the answer depends on opinion, context, and individual variation. But if you ask "What is the statute of limitations for breach of contract in California?" there is a definitive answer in the California Code of Civil Procedure, and a RAG system can retrieve it.
Major legal publishers have spent decades curating the databases that RAG systems now query. Thomson Reuters (Westlaw), LexisNexis, and Bloomberg Law have invested heavily in organizing, indexing, and maintaining legal content. RAG allows legal AI tools to leverage that curation work rather than trying to replicate it inside a neural network.
Concrete Data: How Much Does RAG Reduce Hallucinations?
The most frequently cited evidence for RAG's effectiveness in legal contexts comes from the Stanford RegLab and HAI study, which tested tools in May 2024. The study found that RAG-based legal research tools hallucinated at substantially lower rates than general-purpose LLMs. However, the data also shows that RAG does not eliminate hallucinations — it reduces them.
| System | Hallucination Rate (May 2024 Testing) | Architecture |
|---|---|---|
| Lexis+ AI | 17% | RAG-based |
| Westlaw AI-Assisted Research | 34% | RAG-based |
| GPT-4 (general purpose) | 43% | Parametric memory only |
The study also identified three unique error modes for RAG-based legal AI that do not occur with general LLMs: retrieval failure (the system cannot find the right authority), inapplicable authority (the retrieved document is not binding due to jurisdictional differences), and sycophancy (the system agrees with the user's incorrect premise rather than correcting it). These error modes mean that even a well-designed RAG system requires careful oversight.
A randomized controlled trial published in March 2025 by Schwarcz et al. studied 127 law students using a RAG-powered tool (Vincent AI) on six representative legal tasks. The study found that the RAG tool produced hallucination rates comparable to students using no AI at all, while improving clarity, organization, and professionalism on four of six tasks. In contrast, students using OpenAI's o1-preview — a reasoning model without RAG — produced better analytical work but introduced hallucinations, including occasionally fabricated entirely fictional cases.
The Vals AI Legal Report (October 2025), testing tools from July 2025, found that ChatGPT with web search achieved 80% accuracy on legal queries, compared to legal AI tools at 78-81%, both outperforming the human lawyer baseline of 69%. However, the same report found a 14-point accuracy drop on 50-state multi-jurisdictional surveys, indicating that RAG performance degrades significantly when the retrieval step must cover multiple jurisdictions simultaneously.

Practical Applications of RAG in Legal Practice
RAG is not a theoretical concept — it is already deployed in production legal AI tools across multiple practice areas. The following applications represent the most common use cases documented in the current legal technology market.
- Legal research with citation verification. Tools like Westlaw CoCounsel and Lexis+ AI use RAG to retrieve relevant case law and statutes, then generate answers with citations that link back to the source documents. This is the most mature RAG application in legal practice.
- Contract analysis and clause extraction. RAG systems can retrieve specific clauses from a contract database, compare them against a firm's preferred language, and flag deviations. Thomson Reuters reports that CoCounsel's Extract Contract Data function achieved a 98.8% pass rate in internal benchmarking.
- Deposition and document review. RAG can retrieve relevant deposition transcripts or discovery documents in response to a specific question, reducing the time spent manually searching large document sets.
- Memo drafting grounded in firm precedents. A firm can index its own repository of past memoranda, briefs, and opinion letters. A RAG system can then retrieve the most relevant precedents and help a junior associate draft a new memo that is consistent with the firm's prior work.
- Compliance audits against current regulations. RAG systems can retrieve the latest regulatory text and compare it against a company's policies or procedures, flagging gaps or inconsistencies.
For a detailed comparison of how specific vendors implement RAG in their legal research tools, see our guide on Westlaw CoCounsel vs Lexis+ AI.
Professional Responsibility: What RAG Does and Does Not Change
RAG reduces the risk of AI-generated hallucinations, but it does not eliminate the attorney's professional responsibility obligations. Every ethics opinion and court order on AI use in legal practice — from ABA Formal Opinion 512 to the standing orders issued by over 25 federal judges as of May 2024 — makes clear that the lawyer remains responsible for the accuracy of any work product, regardless of whether it was generated with AI assistance.
The following ABA Model Rules are directly relevant to RAG tool use:
- Model Rule 1.1 (Competence). Comment 8 requires attorneys to "keep abreast of changes in the law and its practice, including the benefits and risks associated with relevant technology." This means a lawyer using a RAG tool must understand how it works well enough to evaluate its output. See our in-depth analysis of ABA Model Rule 1.1 and AI.
- Model Rule 1.6 (Confidentiality). When a lawyer submits a query to a RAG system, the query may contain confidential client information. The lawyer must ensure that the RAG tool's data handling practices do not compromise client confidentiality. This is particularly relevant for cloud-based RAG systems that may retain query data.
- Model Rule 5.3 (Supervision of Nonlawyer Assistants). AI tools are increasingly treated as nonlawyer assistants for supervision purposes. The lawyer must ensure that the RAG system is used appropriately and that its output is reviewed by a competent attorney.
ABA Formal Opinion 512, issued in 2024, provides the most comprehensive guidance on generative AI ethics for attorneys. The opinion requires that lawyers verify AI-generated outputs and maintain competent oversight of any AI tool used in practice. For a thorough breakdown of the opinion's requirements, see our article on ABA Formal Opinion 512.
Limitations and Caveats: When RAG Falls Short
RAG is a significant improvement over general LLMs for legal work, but it is not a magic bullet. Legal professionals should be aware of the following documented limitations.
- Retrieval quality depends on database curation. If the underlying database is incomplete, outdated, or poorly indexed, the RAG system will retrieve the wrong documents. The quality of the output is fundamentally limited by the quality of the retrieval step.
- Jurisdictional complexity degrades performance. The Vals AI Report found a 14-point accuracy drop on 50-state multi-jurisdictional surveys. When a query requires the system to retrieve and synthesize law from multiple jurisdictions, the risk of error increases substantially.
- Sycophancy risk. The Stanford RegLab study identified sycophancy as a distinct error mode for RAG-based legal AI: the system may agree with a user's incorrect premise rather than correcting it. A lawyer who asks "What is the exception to the hearsay rule for business records in California?" with a mistaken premise may receive a plausible-sounding but wrong answer.
- Knowledge cutoff issues. Even with RAG, the underlying LLM has a knowledge cutoff date. A 2025 study found that OpenAI's o3 model applied the overruled Chevron doctrine to a post-Loper Bright query because its training data did not include the Supreme Court's decision. RAG can mitigate this if the database includes the new decision, but only if the retrieval step finds it.
- RAG does not eliminate hallucinations entirely. Even the best RAG systems hallucinate at rates of 17-34% (per the Stanford RegLab study). The LLM may still fabricate citations, misstate the law, or draw incorrect inferences from the retrieved documents.
For a broader look at how these limitations have played out in real court cases and sanctions, see our AI Hallucinations and Attorney Ethics article, which covers documented incidents and escalating sanctions.
References and Further Reading
The following sources were consulted in the preparation of this glossary entry. They are listed here for independent verification and further exploration.
- Stanford HAI: AI on Trial — Legal Models Hallucinate in 1 out of 6 (or More) Benchmarking Queries (Magesh et al., 2024-2025)
- AI Law Librarians: What the Science Says About Hallucinations in Legal Research (synthesis of multiple studies)
- Harvard Journal of Law & Technology: Retrieval-Augmented Generation (RAG) (architectural overview)
- Thomson Reuters: Intro to RAG in Legal Tech (vendor perspective with CoCounsel benchmarks)
- LegalBench-RAG: A Benchmark for Retrieval-Augmented Generation in the Legal Domain (arXiv, 2024)
- Schwarcz et al.: AI-Powered Lawyering — AI Reasoning Models, Retrieval Augmented Generation, and the Future of Legal Practice (SSRN, March 2025)
For deeper dives into related topics on this site, see our AI Hallucination Benchmarks comparison guide, our ABA Model Rule 1.1 and AI analysis, and our ABA Formal Opinion 512 breakdown.
Comments
Join the discussion with an anonymous comment.