The Harvey AI Risk Landscape: Why This Analysis Is Necessary
Harvey AI has become the most visible and best-capitalized generative AI platform in the legal industry. As of June 2026, the company reports that more than 142,000 lawyers across 1,500 organizations in 60 countries use its products. Its valuation reached $11 billion in March 2026 after a $200 million round co-led by GIC and Sequoia, and its annual recurring revenue hit $190 million in January 2026. These numbers signal deep market conviction that Harvey is not an experiment but a core infrastructure investment for the firms and in-house departments that have adopted it.
But rapid adoption and high valuation do not eliminate professional risk. They concentrate it. When a platform reaches the scale Harvey has achieved, a single hallucination incident, a single ethical wall breach, or a single sanctions order can cascade across dozens of firms and hundreds of matters simultaneously. Risk officers, professional responsibility counsel, and managing partners need a Harvey-specific risk assessment — not another general article about AI hallucinations in court filings or a broad overview of ABA ethics opinions. The existing coverage on this site addresses those general topics. This article is different: it examines the specific gap between Harvey's reliability claims and the operational verification burden that professional responsibility rules impose, and it identifies the failure modes that Harvey's own technical leadership has flagged for its AI agent architecture.
The Hallucination Evidence Base: Harvey's Own Data vs. Independent Research
Any honest risk assessment of Harvey must begin with the contested hallucination rate data, because the entire value proposition of a legal AI tool rests on the trustworthiness of its output. If a lawyer cannot rely on the accuracy of what Harvey produces, the efficiency gains it promises are consumed by the verification work required to catch errors. The problem is that the available data points paint two very different pictures, and neither can be dismissed.
Harvey's Self-Reported Rate: 0.2% on BigLaw Bench
In October 2024, Harvey published a study on its own blog introducing the BigLaw Bench, a set of evaluation tasks designed to measure hallucination rates in legal AI outputs. Harvey defined a hallucination as "a factual claim made by an LLM that can be demonstrably disproven by reference to a source of truth." On these tasks, Harvey's Assistant model hallucinated approximately 1 in 500 claims — a 0.2% rate. For comparison, the same study found that Claude hallucinated at 0.7% (1 in 150), ChatGPT at 1.3% (1 in 77), and Gemini at 1.9% (1 in 110). Harvey's models produced longer and more detailed answers than the foundation models while maintaining a lower hallucination rate.
Independent Research: ~17% Hallucination Rate for Legal AI Tools
In May 2024, Stanford's Human-Centered AI (HAI) research group published a study testing leading legal AI research tools. The researchers found that specialized legal AI tools hallucinated in roughly one of every six queries — approximately 17%. Lexis+ AI hallucinated in about 17% of queries; Westlaw AI-Assisted Research performed worse; and general-purpose LLMs fabricated information in well over half of responses. The study identified two distinct failure modes: the AI describes the law incorrectly, or the AI describes the law correctly but cites sources that do not actually support its claims. The second failure mode is especially insidious because it can appear credible to a lawyer who does not independently verify every citation.
These two data points — 0.2% and 17% — are not directly comparable. They measure different scopes (Harvey's Assistant model on a specific benchmark versus multiple legal AI tools on open-ended legal research queries), use different methodologies (proprietary versus academic), and were conducted at different times (October 2024 versus May 2024). But the gap between them is too large to ignore. A risk officer evaluating Harvey must ask: which number better reflects the tool's performance in the uncontrolled, varied workflows of daily practice?
| Source | Reported Rate | Scope | Methodology | Date |
|---|---|---|---|---|
| Harvey (BigLaw Bench) | 0.2% (1 in 500 claims) | Harvey Assistant model on proprietary benchmark | Vendor-designed, self-reported | October 2024 |
| Stanford HAI | ~17% (1 in 6 queries) | Multiple legal AI tools on legal research queries | Independent academic study | May 2024 |
| Vals AI Benchmark | Harvey ranked #1 overall | 4 legal AI tools across 7 tasks vs. human baseline | Vendor cooperation, full product access | February 2025 |
The April 2026 Fake LexisNexis Citation Incident
Beyond the contested benchmark data, a specific documented incident involving Harvey surfaced in April 2026. A user reported that Harvey generated a fake LexisNexis citation — a fabricated source that appeared authentic but did not exist. The incident was documented on LinkedIn, where it drew more than 600 reactions and generated weeks of discussion across legal Twitter. While this is a single data point and not a systematic study, it is significant because it demonstrates that Harvey's outputs can and do produce the same category of citation hallucination that has led to sanctions in other cases.
The Verification Paradox Defined
The central governance challenge of deploying Harvey in a law firm is what this analysis calls the verification paradox. Harvey's value proposition is built on efficiency: the company reports that in-house users save an average of more than 25 hours per month, and its platform maintains a 92% monthly adoption rate across its customer base. But ABA Formal Opinion 512, issued in July 2024, requires that lawyers treat generative AI output like the work of an "inexperienced or overconfident nonlawyer assistant" and verify every output before using it in client work.
The paradox is straightforward: if every Harvey output must be verified by a human attorney, and if that verification process is itself time-consuming, then the net efficiency gain may be far smaller than the vendor's marketing suggests. In the worst case, the verification burden can consume the efficiency gains entirely, leaving the firm with the cost of the tool and the liability of the output but none of the promised productivity benefit.
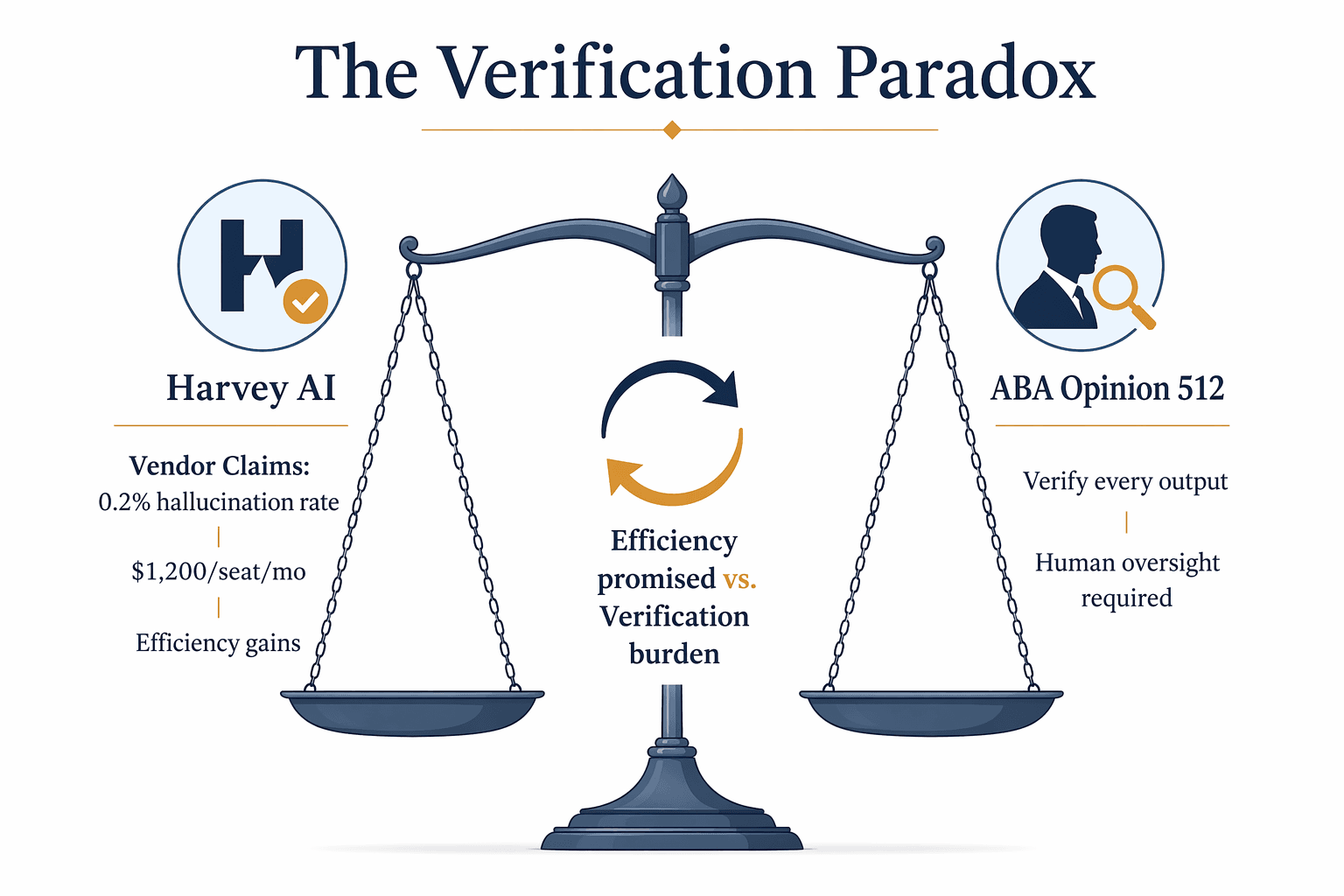
This is not a theoretical concern. Paul Weiss, one of Harvey's earliest and most prominent testers, spent nearly 18 months evaluating the platform before rolling it out more broadly. Gina Lynch, Paul Weiss's partner in charge of legal technology, told the press that the firm did not use hard metrics like time saved because, in her words, "checking the AI system was so involved that it makes any efficiency gains difficult to measure." If a firm of Paul Weiss's resources and sophistication could not quantify the efficiency benefit after 18 months of testing, smaller firms with less dedicated technology support should be cautious about assuming that Harvey will deliver the productivity improvements it advertises.
ABA Formal Opinion 512: What It Requires of Harvey Users
ABA Formal Opinion 512, issued in July 2024, is the most authoritative professional responsibility guidance on generative AI use in legal practice. While the opinion addresses AI generally and does not name Harvey specifically, its principles directly govern every firm that deploys Harvey. The opinion's core requirements, as they apply to Harvey users, can be summarized as follows.
- Treat AI as an inexperienced or overconfident nonlawyer assistant. The opinion explicitly analogizes generative AI to a junior associate or paralegal who may be overconfident in their own accuracy. Lawyers must apply the same supervisory standards they would to a human assistant — which means verifying all work product before using it.
- Verify all output. The opinion does not carve out exceptions for tools with low hallucination rates. A 0.2% error rate on a benchmark does not satisfy the duty of competence under Model Rule 1.1. Every citation, every legal conclusion, every factual assertion generated by Harvey must be independently verified against primary sources.
- Competence obligations under Model Rule 1.1. Lawyers must understand the technology they are using well enough to assess its risks and limitations. This includes understanding how Harvey's underlying models work, what data they were trained on, and what failure modes are documented. A lawyer who cannot explain why Harvey might hallucinate a citation has not satisfied the competence duty.
- Confidentiality duties under Model Rule 1.6. Lawyers must ensure that client confidential information is not disclosed to the AI vendor or used for model training. This requires reviewing Harvey's data retention and training data policies, understanding whether queries are logged and retained, and ensuring that any contract with Harvey includes appropriate confidentiality provisions.
Harvey itself acknowledges these obligations. In a June 2026 guide published on its own blog, the company states that ABA Formal Opinion 512 "requires treating AI as an 'inexperienced or overconfident nonlawyer assistant' — all output must be verified by a human attorney." The guide further notes that "every rule that governed your practice before AI governs it now, in full." This is a responsible position for a vendor to take, but it also means that Harvey's marketing claims about efficiency must be read in light of the verification burden the company itself acknowledges.
Ethical Wall Failure Modes for AI Agents: Harvey's Own Identified Risks
One of the most significant risk developments in the Harvey ecosystem came not from a critic or a regulator but from Harvey's own chief technology officer, Gabe Pereyra. In a March 2026 blog post titled "Long Horizon Agents and Ethical Walls," Pereyra identified three novel ethical wall failure modes that arise specifically when AI agents — not just chatbots — operate within a law firm's environment. These failure modes are distinct from the traditional ethical wall risks that law firms have managed for decades, and they require fundamentally different controls.
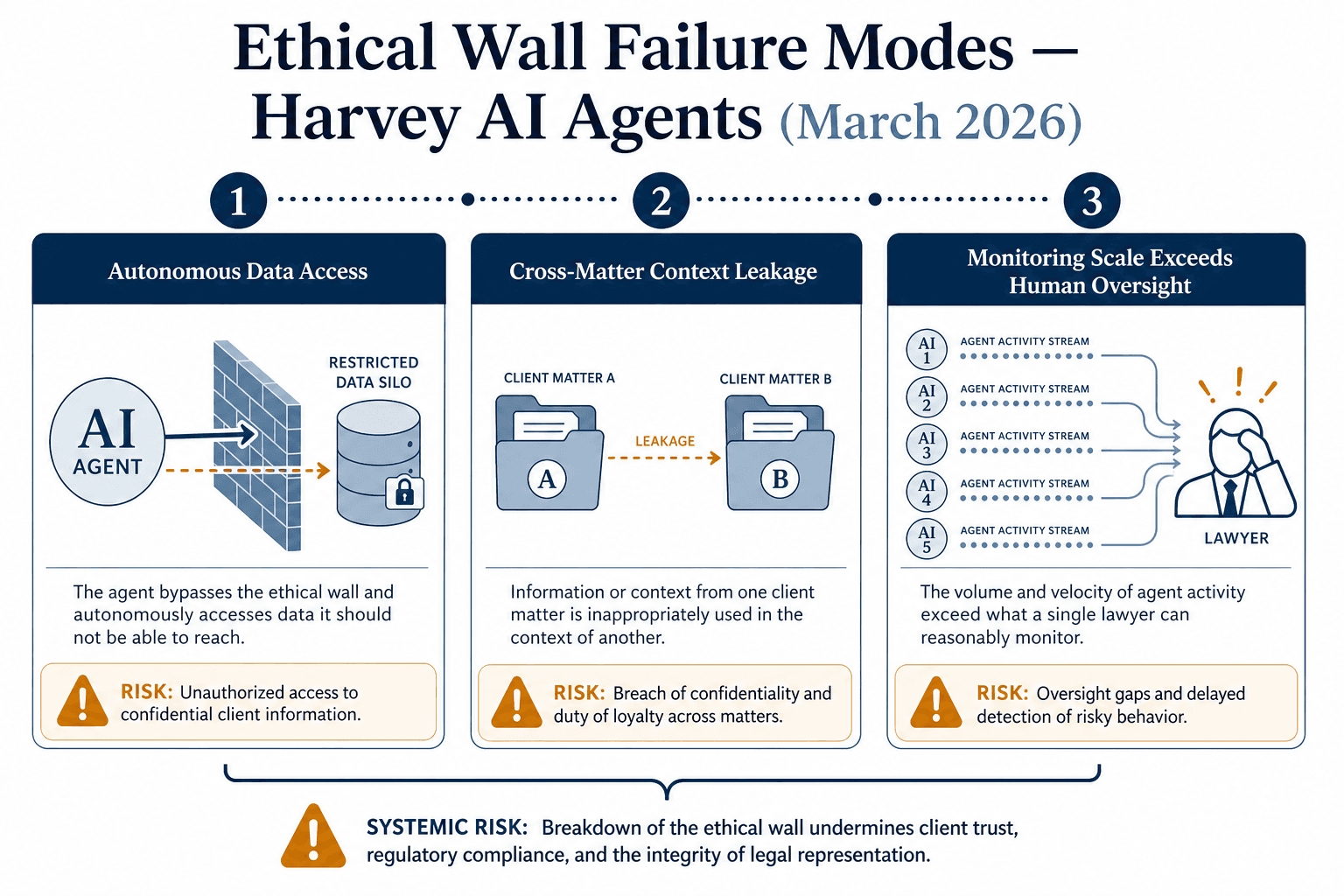
Failure Mode 1: Autonomous Data Access Beyond Lawyer Permissions
Traditional document management systems (DMS) control access at the point of entry: a lawyer can only open documents they have permission to see. But an AI agent does not work that way. When an agent is given a task — say, "find all documents related to this merger" — it may autonomously traverse the DMS, retrieving documents from matters the supervising lawyer does not work on. The agent processes whatever it retrieves without knowing to stop at an access boundary. Pereyra's post warns that traditional "fail open" DMS access controls are "catastrophic" for AI agents because the agent will exploit any access it has been granted, even if that access was intended for a different purpose.
Failure Mode 2: Cross-Matter Context Leakage
AI agents maintain context across time. If an agent works on Matter A in the morning and Matter B in the afternoon, the context from Matter A can theoretically contaminate Matter B. This is not a hypothetical risk: Pereyra explicitly identifies "cross-matter context leakage" as a failure mode that ethical wall systems must address. In a traditional law firm, ethical walls are enforced by physically separating teams and document repositories. An AI agent, by contrast, carries its context with it — and if that context includes confidential information from a client on the other side of a wall, the wall has been breached.
Failure Mode 3: Monitoring Scale Exceeds Human Oversight
The third failure mode is perhaps the most fundamental. An AI agent can process hundreds of documents in minutes, executing thousands of retrieval and reasoning steps in the time it takes a human lawyer to review a single document. The supervising lawyer cannot review every intermediate step the agent took. Pereyra's post states this plainly: agents "operate at a scale humans cannot monitor." This creates a governance gap: if the supervising lawyer cannot audit the agent's reasoning path, how can the lawyer certify that no ethical wall was breached?
The Precedent: Mata v. Avianca and 850+ Documented AI Hallucination Cases
The risk of AI-generated hallucinations in legal practice is not theoretical. It has already produced real sanctions, real malpractice exposure, and real damage to attorney credibility. The most famous case is Mata v. Avianca, decided in 2023, in which a lawyer used ChatGPT to draft a brief that cited six nonexistent cases. The court imposed $5,000 in sanctions and the lawyer faced professional discipline. That case became a watershed moment for the legal profession's awareness of AI hallucination risk.
But Mata v. Avianca is not an isolated incident. An AI Hallucination Cases Database now tracks more than 850 documented court cases worldwide where AI-generated hallucinations affected court filings. U.S. courts alone have imposed more than $145,000 in sanctions related to AI-generated fabricated citations. In October 2025, Gordon Rees, an Am Law 71 firm, publicly apologized for submitting bankruptcy filings that contained fabricated citations generated by AI. These are not minor or marginal cases — they involve major law firms, significant sanctions, and public reputational damage.
| Incident | Date | AI Tool | Outcome |
|---|---|---|---|
| Mata v. Avianca | 2023 | ChatGPT | $5,000 sanctions, fabricated citations |
| Gordon Rees bankruptcy filings | October 2025 | Unspecified AI tool | Public apology, fabricated citations |
| Harvey fake LexisNexis citation | April 2026 | Harvey | 600+ LinkedIn reactions, community documentation |
For risk officers evaluating Harvey, these precedents serve two functions. First, they establish that AI hallucination is a real and recurring problem in legal practice — not a theoretical risk that can be dismissed with vendor benchmarks. Second, they demonstrate that courts are willing to impose sanctions when lawyers fail to verify AI-generated output. A firm that deploys Harvey without a robust verification protocol is exposing itself to the same category of liability that has already produced millions of dollars in sanctions and settlements across the industry.
A Practical Governance Framework for Harvey Deployment
The analysis above identifies real risks, but it does not argue that firms should avoid Harvey. Harvey is a powerful tool that, when deployed with appropriate governance, can deliver genuine value. The question is not whether to use Harvey but how to use it responsibly. The following governance framework is designed for risk officers, managing partners, and professional responsibility counsel who are evaluating or already managing a Harvey deployment.
1. Require Integration with Existing Conflicts and DMS Infrastructure
Harvey's own CTO has stated this requirement explicitly. Any deployment of Harvey Workflow Agents must integrate with the firm's existing conflicts system (such as Intapp) and document management system (such as iManage or NetDocuments). Without these integrations, the ethical wall failure modes identified above cannot be effectively controlled. The integration should enforce matter-level access controls, not user-level controls: an agent should only be able to access documents and data that belong to the specific matter it is working on.
2. Insist on Auditable Logging
Every action an AI agent takes — every document retrieved, every query executed, every reasoning step — must be logged in a format that can be audited by the supervising lawyer and, if necessary, by the firm's conflicts department or outside counsel. The log must be immutable (not editable by the agent or the user) and must be retained for the same period as the firm's other matter records. Without auditable logging, the firm cannot certify that no ethical wall was breached, and it cannot defend itself in the event of a malpractice claim.
3. Implement Matter-Centric Product Isolation
Harvey's platform should be configured so that each matter operates in an isolated environment. The agent working on Matter A should have no access to the context, data, or history of Matter B. This is not how most AI platforms are designed by default — they tend to accumulate context across sessions — but it is essential for ethical wall compliance. Firms should work with Harvey's implementation team to ensure that matter isolation is enforced at the platform level, not just at the user behavior level.
4. Establish Verification Protocols That Account for the Verification Paradox
The verification paradox means that firms cannot simply assume that Harvey's outputs are accurate and move on. They must budget for verification time explicitly. This might mean assigning a junior associate or paralegal to verify every Harvey-generated citation before it is used in a filing, or building a two-step review process into the workflow. The key is to measure the verification cost and compare it to the efficiency gain, rather than assuming the gain is automatic.
5. Set Clear Policies for Permitted and Prohibited Workflows
Not every legal workflow is appropriate for AI assistance. Firms should define, in writing, which workflows Harvey can be used for and which workflows require human-only execution. For example, Harvey may be appropriate for initial document review, contract analysis, and legal research — provided that all output is verified. It may not be appropriate for final drafting of court filings, for client communications that contain legal advice, or for any workflow where a hallucination could cause irreparable harm. These policies should be reviewed and updated as Harvey's capabilities evolve.
| Governance Requirement | Why It Matters | Implementation Priority |
|---|---|---|
| Conflicts/DMS integration | Prevents autonomous data access beyond lawyer permissions | Critical — required before agent deployment |
| Auditable logging | Enables post-hoc verification and defense against malpractice claims | Critical — required before agent deployment |
| Matter-centric isolation | Prevents cross-matter context leakage | High — required for any multi-matter use |
| Verification protocols | Addresses the verification paradox and ABA Opinion 512 compliance | High — required for all use |
| Permitted workflow policies | Limits exposure to high-risk use cases | Medium — should be in place before firm-wide rollout |
Conclusion: The Efficiency-Verification Tradeoff Is Not Going Away
Harvey AI is not a passing trend. With more than 142,000 lawyers using the platform, $190 million in annual recurring revenue, and an $11 billion valuation, it has become a permanent feature of the legal technology landscape. The firms that succeed with Harvey will not be the ones that trust it most blindly. They will be the ones that treat governance as a first-class requirement — budgeting for verification time, integrating with existing conflicts infrastructure, implementing auditable logging, and setting clear policies for what the tool can and cannot do.
The verification paradox is not a bug in Harvey. It is a structural feature of deploying generative AI in a profession that holds its practitioners personally responsible for the accuracy of every statement they make. The firms that acknowledge this paradox and design their workflows around it will capture the genuine efficiency gains that Harvey offers. The firms that ignore it — that treat Harvey's 0.2% self-reported hallucination rate as a guarantee rather than a benchmark — will find themselves on the wrong side of a sanctions order, a malpractice claim, or an ethical wall breach.
The choice is not between using Harvey and not using it. The choice is between deploying Harvey with governance and deploying it without. The evidence reviewed in this analysis — from Harvey's own CTO's warnings to the 850+ documented hallucination cases to the requirements of ABA Formal Opinion 512 — points clearly to which choice is professionally responsible.
Comments
Join the discussion with an anonymous comment.