What Is a Large Language Model (LLM)? The Core Definition
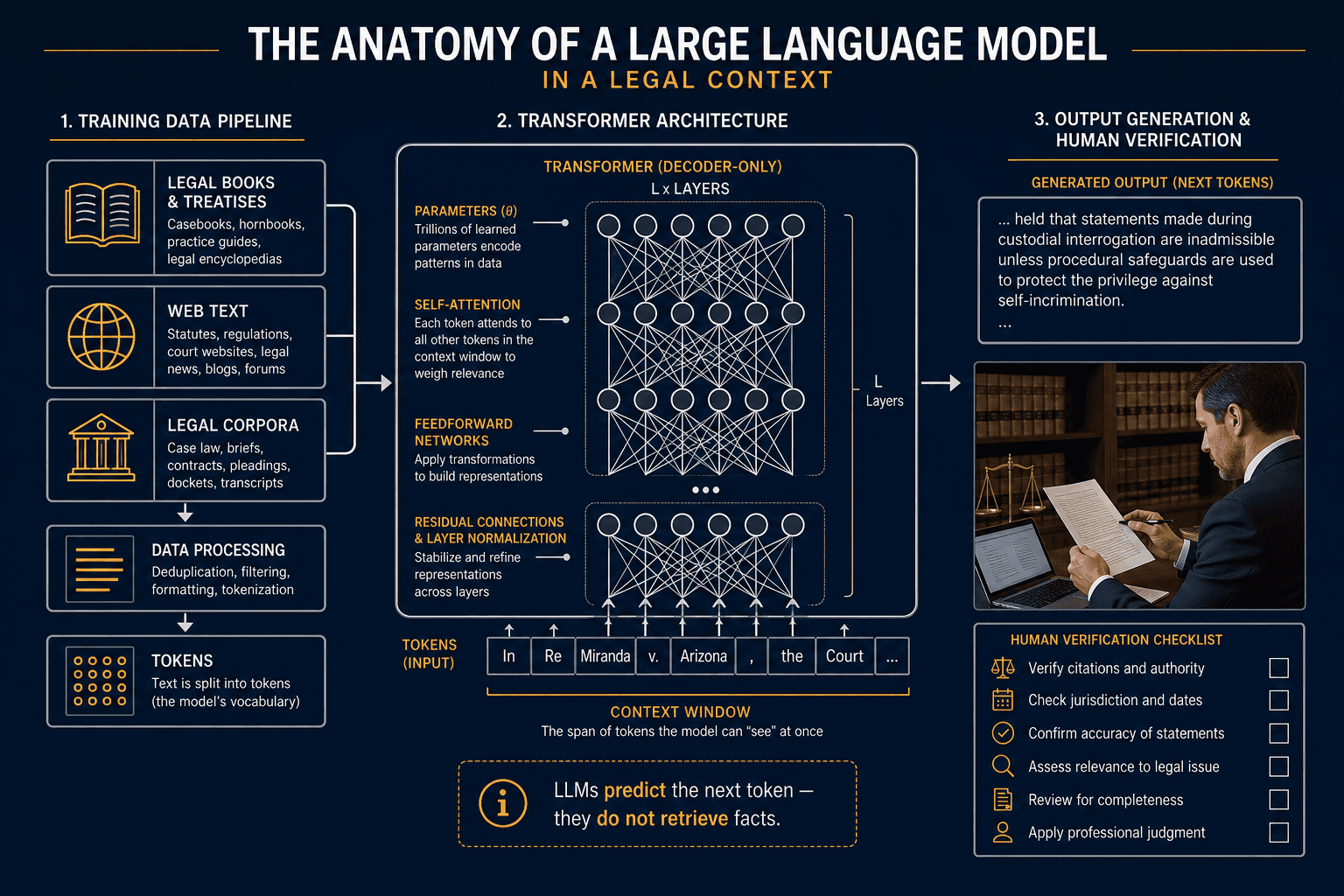
A large language model (LLM) is a type of neural network trained on massive collections of text — often terabytes of data — using a transformer architecture to predict and generate sequences of natural-language tokens. In plain terms, an LLM is a pattern-recognizing and pattern-generating machine. It learns the statistical relationships between words, phrases, and sentences from its training data, then uses those learned patterns to produce text that resembles human writing.
The transformer architecture, introduced in the 2017 paper "Attention Is All You Need" by Vaswani et al. at Google Brain, is the foundational design that made modern LLMs possible. Unlike earlier neural network designs that processed text sequentially, transformers use a mechanism called self-attention that allows the model to weigh the importance of every word in a passage relative to every other word. This enables the model to capture long-range dependencies — for example, understanding that a pronoun in paragraph three refers back to a noun introduced in paragraph one.
The "large" in "large language model" refers to two things simultaneously: the number of parameters (internal variables the model learns during training) and the volume of training data. Early models like GPT-2 had 1.5 billion parameters; later models such as PaLM reached 540 billion parameters. The training data for these models is measured in terabytes — the Common Crawl dataset alone contains data from more than 3 billion web pages.
Crucially, an LLM does not retrieve information from a live database when it generates a response. It does not "look up" facts. Instead, it generates each token — a word, part of a word, or punctuation mark — one at a time, based on the probability distribution it learned during training, conditioned on the prompt you provided. This distinction is the single most important concept for legal professionals to understand, because it directly explains both the capabilities and the failure modes of every LLM-powered legal tool on the market.
How LLMs Differ from Traditional Legal Technology
Legal professionals have decades of experience with tools that operate on fundamentally different principles: Boolean search engines, rule-based expert systems, and extractive AI. Understanding how LLMs differ from these familiar technologies is essential for evaluating when to trust — and when to verify — an LLM's output.
| Technology | How It Works | Key Limitation |
|---|---|---|
| Boolean search (Westlaw, LexisNexis) | Matches exact keywords and operators against a curated, indexed database of legal documents. | Returns only documents that contain the exact search terms; cannot generate summaries or answer novel questions. |
| Rule-based expert systems | Applies hand-coded if-then rules written by domain experts to reach deterministic conclusions. | Brittle and expensive to maintain; cannot handle ambiguity or cases the rules did not anticipate. |
| Extractive AI | Identifies and extracts specific data points (dates, party names, clauses) from documents using pattern matching or classification models. | Cannot generate new text; limited to identifying what is already present in the source document. |
| Large language models (generative AI) | Predicts and generates tokens based on probabilistic patterns learned from training data. | Can produce confidently wrong or fabricated information; no built-in mechanism for factual verification. |
The most common misconception among legal professionals is treating an LLM like an enhanced search engine. A search engine retrieves documents from a known, curated database and presents them for your review. An LLM generates new text that resembles the kind of text it was trained on. When you ask an LLM to summarize a case, it does not pull up the case from a database — it generates a summary that looks like the case summaries it saw during training. If the training data contained errors, or if the model misremembers a detail, the output will be wrong, even if it is formatted perfectly.
The Training Pipeline: Pre-Training, Fine-Tuning, and RAG
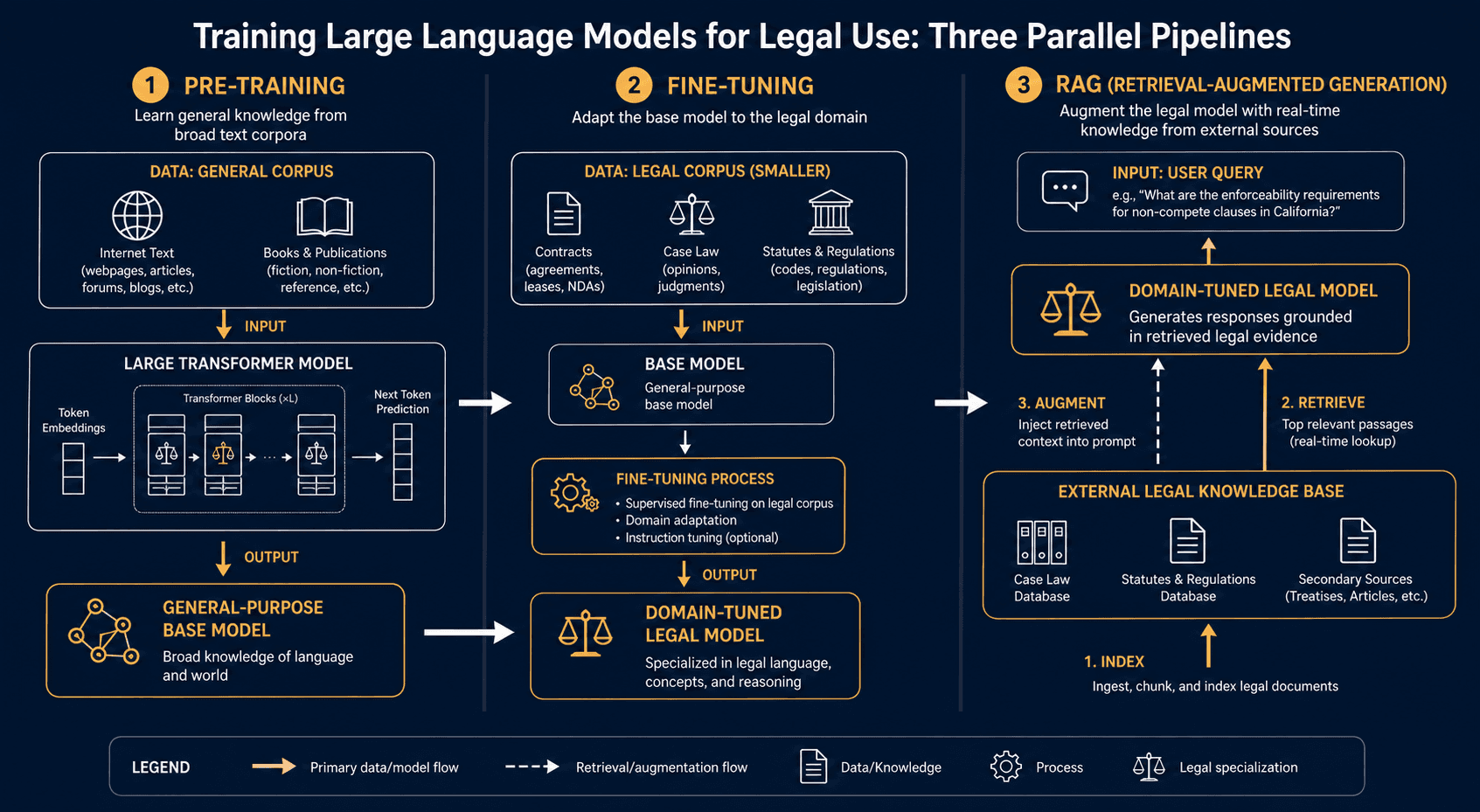
Understanding how an LLM is built — and where each stage introduces risks — is critical for evaluating legal AI tools. The lifecycle of a legal LLM typically involves three distinct phases.
Pre-Training
Pre-training is the initial phase where the model is trained on a vast, general corpus of text — books, articles, websites, academic papers, and other publicly available content. During this phase, the model learns grammar, syntax, factual associations, reasoning patterns, and the statistical structure of language. The model does not "know" anything in the human sense; it has learned that certain sequences of tokens are more probable than others. A model pre-trained only on general text can hold a conversation and answer general knowledge questions, but it will lack domain-specific legal knowledge.
Fine-Tuning
Fine-tuning takes a pre-trained model and continues training it on a smaller, domain-specific dataset — in this case, legal documents, case law, statutes, contracts, and legal commentary. This process adjusts some of the model's parameters to shift its output distribution toward legal language and reasoning patterns. Fine-tuning can make the model better at tasks like contract clause identification or legal question answering.
However, fine-tuning does not guarantee factual accuracy. A fine-tuned model can still hallucinate, fabricate citations, or apply outdated law. Fine-tuning adjusts the model's style and domain relevance, but it does not give the model a reliable internal fact-checking mechanism.
Retrieval-Augmented Generation (RAG)
RAG is a technique that adds an external retrieval step to the LLM's process. Before the model generates a response, a separate retrieval system searches a specified database — such as a firm's document repository, a curated legal database, or a set of relevant statutes — and returns relevant documents. The LLM then uses those retrieved documents as context to generate its response, rather than relying solely on its internal training data.
RAG significantly reduces — but does not eliminate — hallucination risk. The Stanford HAI study (Magesh et al., May 2024) tested three legal AI tools, including two that use RAG, and found that they still produced incorrect information at rates of 17% or higher. RAG systems can fail when the retrieval step returns irrelevant documents, when the model misinterprets the retrieved text, or when the retrieved text itself contains errors.
For a deeper explanation of how RAG works and its specific applications in legal practice, see our dedicated RAG glossary entry.
Key Architectural Concepts Every Legal Professional Should Understand
Several technical terms appear in every discussion of LLMs. Understanding these concepts at a practical level will help you evaluate vendor claims, assess tool limitations, and communicate effectively with technical teams.
| Concept | Definition | Why It Matters for Legal Work |
|---|---|---|
| Token | The basic unit of text that an LLM processes. A token can be a word, part of a word, or a punctuation mark. For example, "unconstitutional" might be split into three tokens: "un", "constitution", "al". | Context windows are measured in tokens, not words. A 4,000-token window holds roughly 3,000 words of English text — less than a typical 10-page contract. |
| Context window | The maximum number of tokens the model can consider at one time. When the window is full, the oldest tokens are dropped and permanently forgotten. | Long documents must be chunked or summarized before input. The model cannot "remember" information from earlier in a document once it scrolls past the window limit. |
| Parameter | An internal variable or weight learned during training. Parameters are the "knobs and dials" the model tweaks to minimize prediction error. More parameters generally mean more capacity to learn complex patterns. | Parameter count is a rough proxy for model capability, but not for accuracy. A model with 540 billion parameters can still hallucinate. |
| Knowledge cutoff | The date after which the model has no training data. The model cannot know about events, cases, statutes, or regulations that postdate its cutoff. | An LLM with a 2023 cutoff cannot know about a 2024 Supreme Court decision or a 2025 regulatory change. Always check the cutoff date before relying on the model for current law. |
The context window limitation is particularly important for legal work. If you are reviewing a 50-page merger agreement, you cannot simply paste the entire document into an LLM prompt and expect the model to consider all of it. The model will only "see" the portion that fits within its context window. Information outside that window is not just ignored — it is completely inaccessible to the model at that moment.
Concrete Legal Use Cases: What LLMs Can and Cannot Do
LLMs are already being deployed across a range of legal workflows. The key to using them effectively is understanding where they add genuine value and where they introduce unacceptable risk.
Where LLMs Add Value
- Document summarization: LLMs can produce concise summaries of long documents, deposition transcripts, or case law. This is a pattern-matching task well suited to their capabilities.
- First-draft document generation: LLMs can generate initial drafts of contracts, pleadings, and correspondence based on structured prompts. These drafts require thorough attorney review but can save significant drafting time.
- Research assistance: LLMs can help identify relevant statutes, cases, or secondary sources — but every citation must be independently verified against a primary source.
- E-discovery keyword refinement: LLMs can suggest search terms and Boolean queries based on case facts, helping refine discovery strategies.
- Deposition question drafting: LLMs can generate initial lists of deposition questions based on case theories and document review.
Documented Limitations and Risks
The Stanford HAI study (Magesh et al., May 2024) provides the most rigorous independent benchmark of legal LLM accuracy to date. The researchers constructed a dataset of over 200 open-ended legal queries and tested three legal AI tools. The results are sobering:
| Tool | Hallucination Rate (as of May 2024) | Error Type |
|---|---|---|
| Lexis+ AI | More than 17% | Incorrect answers and misgrounded citations |
| Westlaw AI-Assisted Research | More than 34% | Incorrect answers and misgrounded citations |
| Ask Practical Law AI | More than 17% | Incorrect answers and misgrounded citations |
Comments
Join the discussion with an anonymous comment.