
Full profile
Introduction: The Benchmark vs. Reality Tension
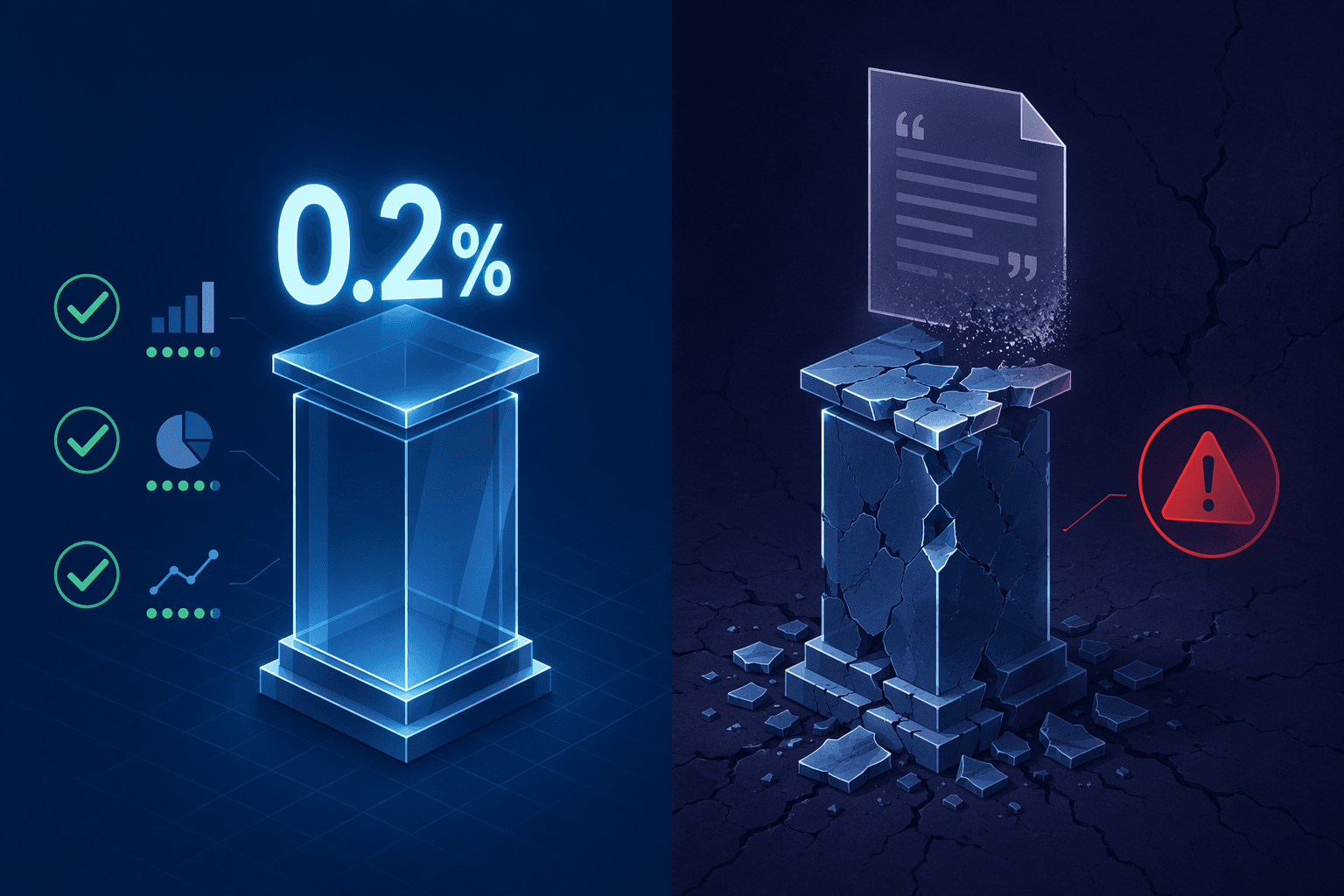
Harvey markets itself on precision. Its October 2024 BigLaw Bench results claim a hallucination rate of 0.2% — one fabricated claim in every 500 — a figure that handily beats every major foundation model on the same test. For a firm paying enterprise-tier rates for a tool that promises to handle complex legal reasoning, that number is the headline. But in April 2026, a lawyer piloting Harvey for its LexisNexis integration watched the platform generate a fake case citation while that integration was actively toggled on. The incident was not an edge case involving an obscure area of law. It was a straightforward citation fabrication that occurred under the very conditions Harvey markets as a safeguard.
This article examines the gap between Harvey's controlled benchmark performance and its documented production failures. It draws on Harvey's own published data — the BigLaw Bench hallucination study and the May 2026 Legal Agent Benchmark (LAB) — alongside user-reported incidents and the April 2026 fabricated citation documented by Joshua Upin, Esq. The goal is not to dismiss Harvey's genuine technical achievements but to give attorneys, professional responsibility officers, and risk managers a clear-eyed assessment of where the platform's accuracy claims hold and where they break down.
Harvey's BigLaw Bench: Methodology and Published Hallucination Rates
In October 2024, Harvey published the results of its internal BigLaw Bench, a benchmark designed to measure hallucination rates on tasks requiring reasoning over multiple, long legal documents. Harvey defines a hallucination as "a factual claim made by an LLM that can be demonstrably disproven by reference to a source of truth." The methodology breaks each model's answer into individual factual claims, then checks each claim against the source documents. Human reviewers validate all model judgments.
The published results position Harvey's Assistant model well ahead of the foundation models it competes against:
| Model | Hallucination Rate | Approximate Frequency |
|---|---|---|
| Harvey Assistant | 0.2% | 1 in 500 claims |
| Claude | 0.7% | 1 in 150 claims |
| ChatGPT | 1.3% | 1 in 77 claims |
| Gemini | 1.9% | 1 in 110 claims |
Comments
Join the discussion with an anonymous comment.