Tool Comparisons
Editorially structured comparison guides that evaluate multiple legal AI tools against a specific user task, firm size, budget, or practice area. Examples include comparisons of AI legal research tools, contract review tools for small firms, and free tools for pro se litigants. Each guide defines evaluation criteria explicitly, cites primary sources or benchmark data where available, and distinguishes independent findings from vendor claims. This group serves users who are actively choosing between options and need a structured decision framework. It does not host individual tool profiles (those belong in tool-profiles) or general educational content about how a workflow operates (that belongs in workflow-guides).
Comparison guides
AI Citation Hallucination: Court Sanctions and Documented Legal Malpractice Incidents
A sourced registry of documented incidents where AI-generated citation hallucinations led to court sanctions, attorney discipline, or malpractice exposure — with case citations, docket references, and professional responsibility implications for each entry.
AI eDiscovery Platform Comparison for Legal Teams: Relativity aiR, Reveal, Logikcull, and Everlaw
A structured side-by-side comparison of four AI-powered eDiscovery platforms — Relativity aiR, Reveal, Logikcull, and Everlaw — evaluated across predictive coding accuracy, data privacy controls, pricing model, and fit for different legal team sizes.
AI Hallucination Benchmarks: What Legal Citation Accuracy Studies Actually Show
A structured review of empirical studies and library evaluations measuring hallucination rates and citation accuracy across legal AI research platforms, with methodology notes and key findings for legal practitioners comparing tools.
AI Hallucination in eDiscovery: Documented Failure Cases and Court Sanctions
A sourced incident record examining documented cases where AI hallucinations caused eDiscovery failures, resulting in court sanctions, adverse findings, and professional responsibility consequences for attorneys.
AI Legal Research Accuracy Benchmarks: Hallucination Rates Compared
A structured review of published empirical studies measuring hallucination rates and citation accuracy across major legal AI research platforms — covering methodology, key findings, and what the numbers actually mean for practitioners choosing between tools.
Harvey vs Casetext: Legal AI Research Platform Comparison
A structured side-by-side comparison of Harvey and Casetext (CoCounsel) across legal research workflows, citation reliability, data privacy, pricing, and firm-size fit — with evidence basis and scope limitations disclosed.
Levidow LeGendre AI Citation Hallucination: Court Sanctions Incident Record
A documented record of the Levidow LeGendre AI citation hallucination incident, in which a New York law firm submitted AI-generated case citations that did not exist, resulting in court sanctions and professional responsibility scrutiny.
Mata v. Avianca: The ChatGPT Citation Hallucination That Led to Court Sanctions (2023)
In 2023, attorneys in Mata v. Avianca submitted a brief citing six AI-generated case citations that did not exist. Judge Castel sanctioned all three attorneys and their law firm $5,000. This incident record documents the docket, the fabricated citations, the court's findings, and the professional responsibility implications.
Westlaw CoCounsel vs. Lexis+ AI: A Practitioner-Focused Comparison
A structured side-by-side comparison of Westlaw CoCounsel and Lexis+ AI across citation reliability, workflow integration, data privacy, pricing, and fit for different firm types and research tasks.

Acorns vs Fidelity Go: What AI Investing Actually Means for Each
This comparison guide helps legal professionals decide between Acorns and Fidelity Go by breaking down fee structures, automation features, and what each platform's AI investing claims actually deliver. It provides a fee break-even analysis and highlights which platform suits different account balances and investing styles.
- Task compared
- Robo-advisor selection for personal investing
- Audience segment
- Legal professionals (associates, paralegals, in-house lawyers)
- Tools covered
- Acorns, Fidelity Go
- Evaluation criteria
- Fee structure, automation features, account types, tax-loss harvesting, fund costs, behavioral design
- Last reviewed
- 2026-07-20

AI Contract Review Buyer's Guide: How to Evaluate Tools (2026)
An independent, criteria-driven framework for GCs, legal ops managers, and law firm partners evaluating AI contract review software. Covers six evaluation criteria, professional responsibility obligations under ABA Model Rules, red flags, and a vendor comparison checklist.
- Task compared
- Evaluating AI contract review software for procurement decisions
- Audience segment
- GCs, legal ops managers, and law firm managing partners
- Tools covered
- LegalOn, Harvey, Kira, LinkSquares, Conga, Ironclad, Spellbook, Definely, goHeather, Luminance, Robin AI, Evisort, Unframe
- Evaluation criteria
- Legal expertise integration, accuracy methodology, security and confidentiality, day-one productivity, workflow integration, pricing transparency, professional responsibility alignment
- Last reviewed
- 2026-06-17

AI Contract Review ROI: Building the Business Case for In-House Legal Teams
This article provides general counsel, chief legal officers, and legal ops managers with the data and framework needed to build a quantifiable business case for AI contract review adoption. It covers baseline cost data, measurable ROI ranges, the critical playbook gap, a staged implementation model, and the change management and risk boundaries that determine whether an investment succeeds or stalls.
- Task compared
- Building a business case for AI contract review adoption
- Audience segment
- General counsel, chief legal officers, and legal ops managers
- Tools covered
- LegalOn, Axiom DraftPilot, Harvey, LEGALFLY
- Evaluation criteria
- Time reduction, cost savings, playbook coverage, change management, risk boundaries
- Last reviewed
- 2026-06-18
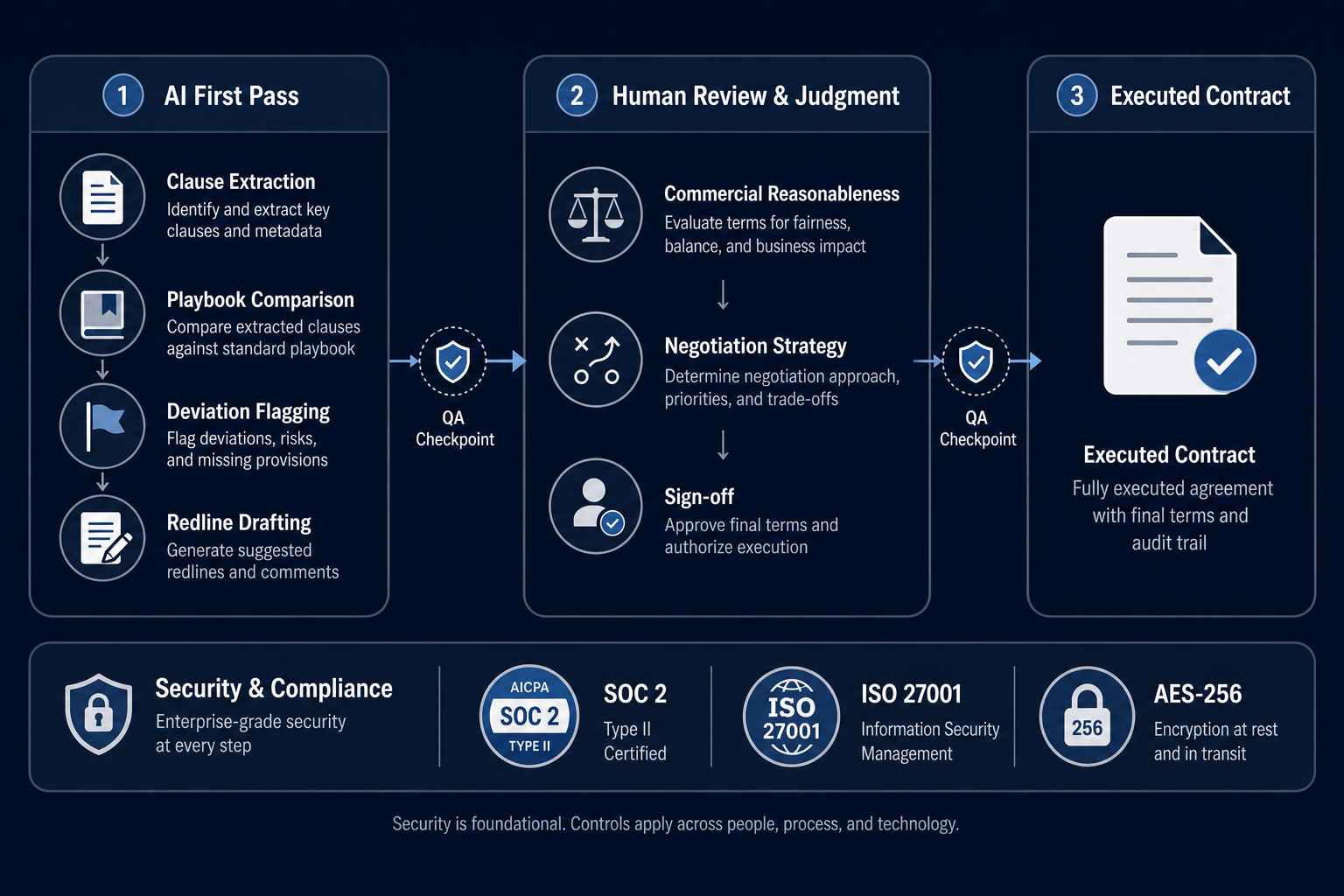
AI Contract Review Security and Data Governance: A Due Diligence Guide for GCs and Compliance Officers
This guide provides general counsel, compliance officers, and legal ops leaders with a structured framework for evaluating the security, data governance, and compliance posture of AI contract review vendors, moving beyond feature comparisons to address mandatory professional responsibility obligations and certification requirements.
- Task compared
- Security and data governance due diligence for AI contract review tools
- Audience segment
- General counsel, compliance officers, legal ops leaders
- Tools covered
- GC AI, DraftPilot (Axiom), Dioptra, Docsum
- Evaluation criteria
- Certifications (SOC 2 Type II, ISO 27001, ISO 42001, GDPR), data training policy, encryption standards, deployment options, DPA terms, audit rights, sub-processor restrictions, cross-border transfer mechanisms
- Last reviewed
- 2026-06-19
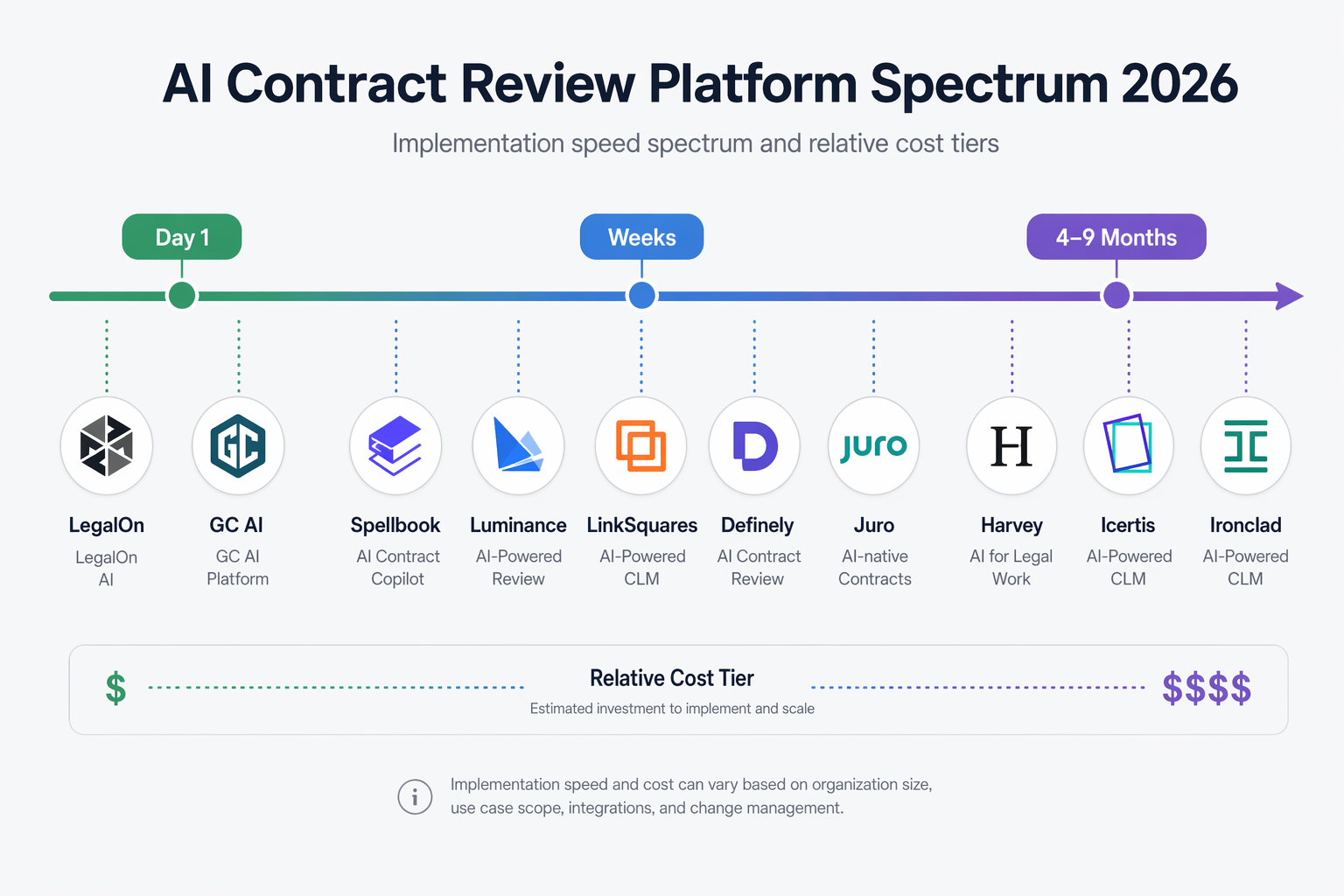
AI Contract Review Software in 2026: A Category-Based Comparison for Legal Teams
This guide organizes the AI contract review market into five distinct platform categories — legal productivity platforms, general legal AI platforms, CLM suites, purpose-built review tools, and Word-native drafting tools — and provides a decision framework to help in-house counsel and legal ops leaders choose the right tool based on contract volume, complexity, implementation timeline, and primary workflow bottleneck.
- Task compared
- AI contract review platform selection by category
- Audience segment
- in-house counsel and legal ops leaders
- Tools covered
- LegalOn, GC AI, Harvey, Ironclad, Icertis, Agiloft, DocuSign CLM, Luminance, LinkSquares, Kira Systems, Robin AI, Juro, Spellbook, Definely
- Evaluation criteria
- platform category, pricing, implementation timeline, key differentiator, best-fit use case
- Last reviewed
- 2026-06-18
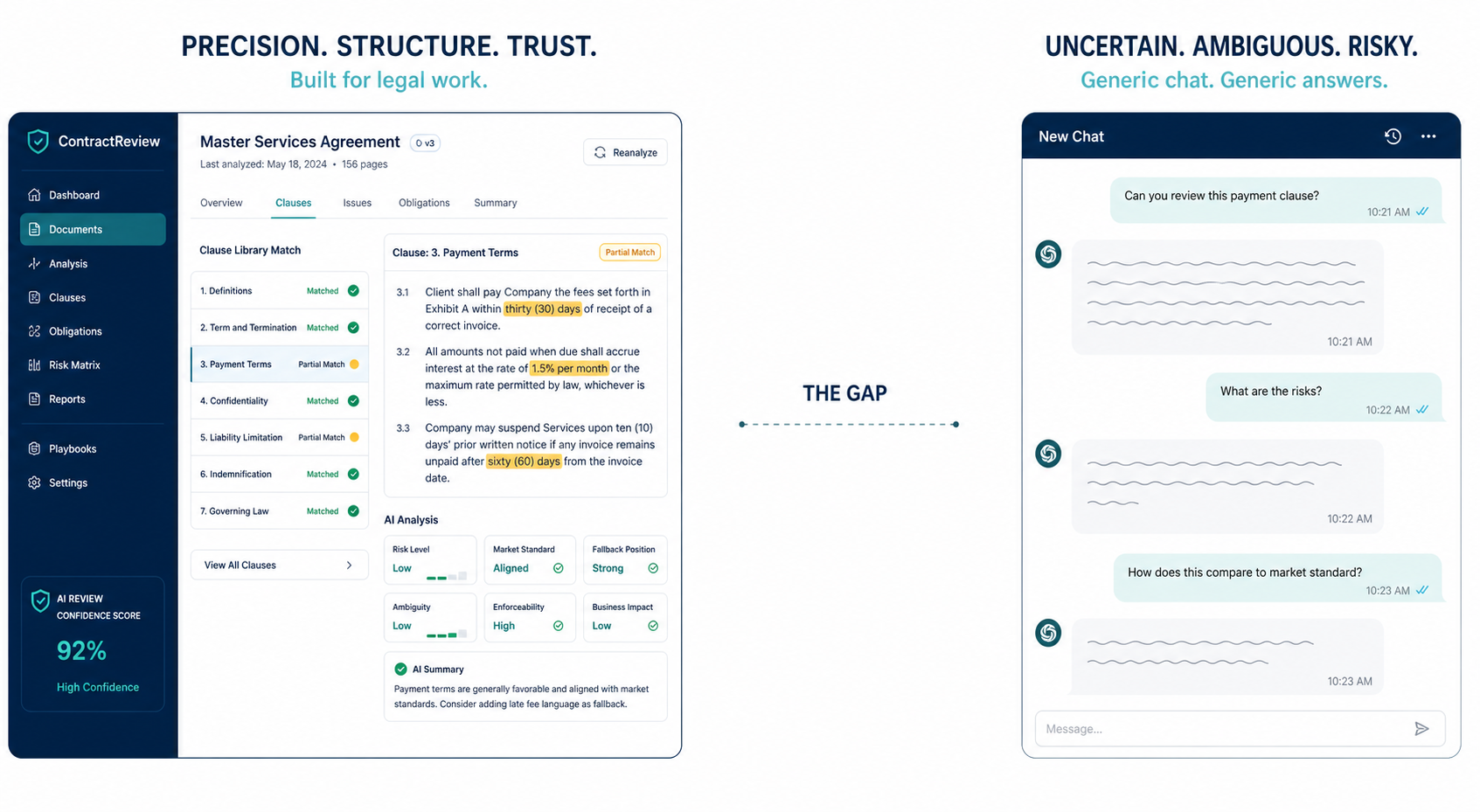
AI Contract Review vs. General-Purpose AI: Why the Gap Persists in 2026
This article compares purpose-built AI contract review tools to general-purpose AI (ChatGPT, Claude) for legal professionals. It explains why general-purpose AI fails on deterministic clause interpretation, playbook enforcement, and character-level citation, and how using it without these guardrails creates ethical exposure under ABA Model Rules 1.1 and 1.6.
- Task compared
- Contract review using purpose-built AI vs. general-purpose AI
- Audience segment
- Legal professionals using ChatGPT or Claude for contract review
- Tools covered
- LegalOn, GC AI, ChatGPT, Claude, Gemini
- Evaluation criteria
- Deterministic clause interpretation, playbook enforcement, character-level citation, accuracy, speed, professional responsibility compliance
- Last reviewed
- 2026-06-18

Which AI Legal Research Tool Should Your Firm Adopt?
This comparison evaluates the five major AI legal research platforms — Lexis+ AI, Westlaw Precision with CoCounsel, vLex Vincent, Harvey, and others — across accuracy benchmarks, real pricing, data confidentiality, and ethics compliance, providing a decision framework for law firm leaders and a verification workflow that no firm can skip.
- Task compared
- legal research query answering and citation verification
- Audience segment
- law firm partners and technology committees
- Tools covered
- Lexis+ AI, Westlaw Precision with CoCounsel, vLex Vincent, Harvey
- Evaluation criteria
- accuracy, completeness, citation verification, source grounding, confidentiality, pricing, sanctions history, security, ethics compliance
- Last reviewed
- 2026-07-09

Find the Best AI Legal Software for Your Practice and Firm Size
This comparison guide evaluates AI legal software tools by practice area and firm size, providing pricing data, accuracy benchmarks, and a shortlist-building framework to help legal professionals select the right stack for their needs.
- Task compared
- Selecting AI legal software by practice area and firm size
- Audience segment
- Law firms and legal departments
- Tools covered
- Lexis+ AI, Westlaw Precision with CoCounsel, vLex Vincent, Bloomberg Law AI, Spellbook, Definely, Kira, Luminance, Harvey AI, Clio Manage AI, MyCase AI, Everlaw, NexLaw, Briefpoint, Lex Machina, Westlaw Litigation Analytics
- Evaluation criteria
- Accuracy, pricing, firm size fit, practice area fit, data privacy, verification requirements
- Last reviewed
- 2026-07-09

AI Replace Lawyers? A Task-by-Task Breakdown of What’s Actually Being Automated — and What Isn’t
This article reframes the binary 'AI replaces lawyers' debate with a granular, data-backed analysis of which specific legal tasks AI automates today and which core human functions remain irreplaceable. Written for practicing attorneys, partners, and legal ops leaders making career and technology investment decisions.
- Task compared
- Task-by-task analysis of AI automation vs. human irreplaceability in legal practice
- Audience segment
- Practicing attorneys at small-to-mid-size firms, law firm partners, and legal operations leaders
- Tools covered
- General-purpose AI tools, AI legal research tools, AI contract review tools, AI e-discovery tools
- Evaluation criteria
- Automation level, accuracy, cost savings, time savings, trust, ethical/regulatory feasibility
- Last reviewed
- 2026-06-17
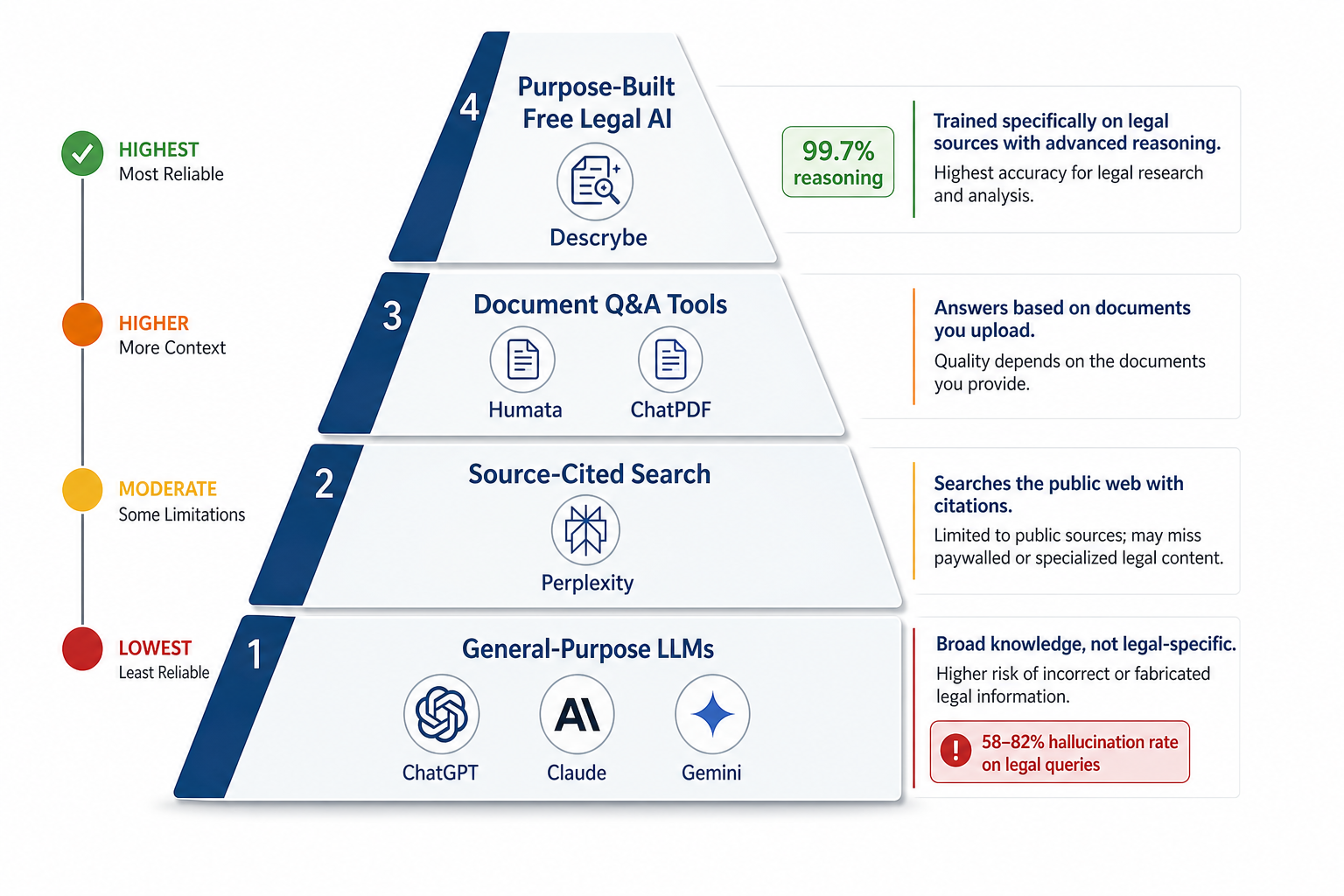
Best Free AI for Legal Research: A Risk-Tiered Comparison for Attorneys
This guide organizes free AI legal research tools into four risk tiers — from general-purpose LLMs to purpose-built legal AI — grounded in the Stanford RegLab hallucination benchmark. It helps attorneys, paralegals, and law students match tool capability to professional responsibility requirements.
- Task compared
- Legal research using free AI tools
- Audience segment
- Attorneys, paralegals, and law students
- Tools covered
- ChatGPT Free, Claude Free, Gemini Free, Perplexity Free, Humata Free, ChatPDF, Descrybe Free, Google Scholar + Gemini
- Evaluation criteria
- Risk tier, free-tier limits, privacy posture, hallucination risk, best-fit use case, verification burden
- Last reviewed
- 2026-06-14

Which AI Tool Works Best for Pro Se Litigants?
This comparison guide evaluates dedicated pro se AI platforms (Prosei, Cetient, AI Lawyer, Courtroom5) against general chatbots (ChatGPT, Claude, Gemini) on hallucination risk, citation accuracy, case management, privacy, and cost. It helps legal professionals understand the strengths and limitations of each option for advising or facing pro se litigants.
- Task compared
- Pro se litigation support
- Audience segment
- Pro se litigant
- Tools covered
- Prosei AI, Cetient, AI Lawyer, Courtroom5, ChatGPT, Claude, Gemini
- Evaluation criteria
- Hallucination risk, citation accuracy, case management, deadline tracking, privacy, cost
- Last reviewed
- 2026-07-09
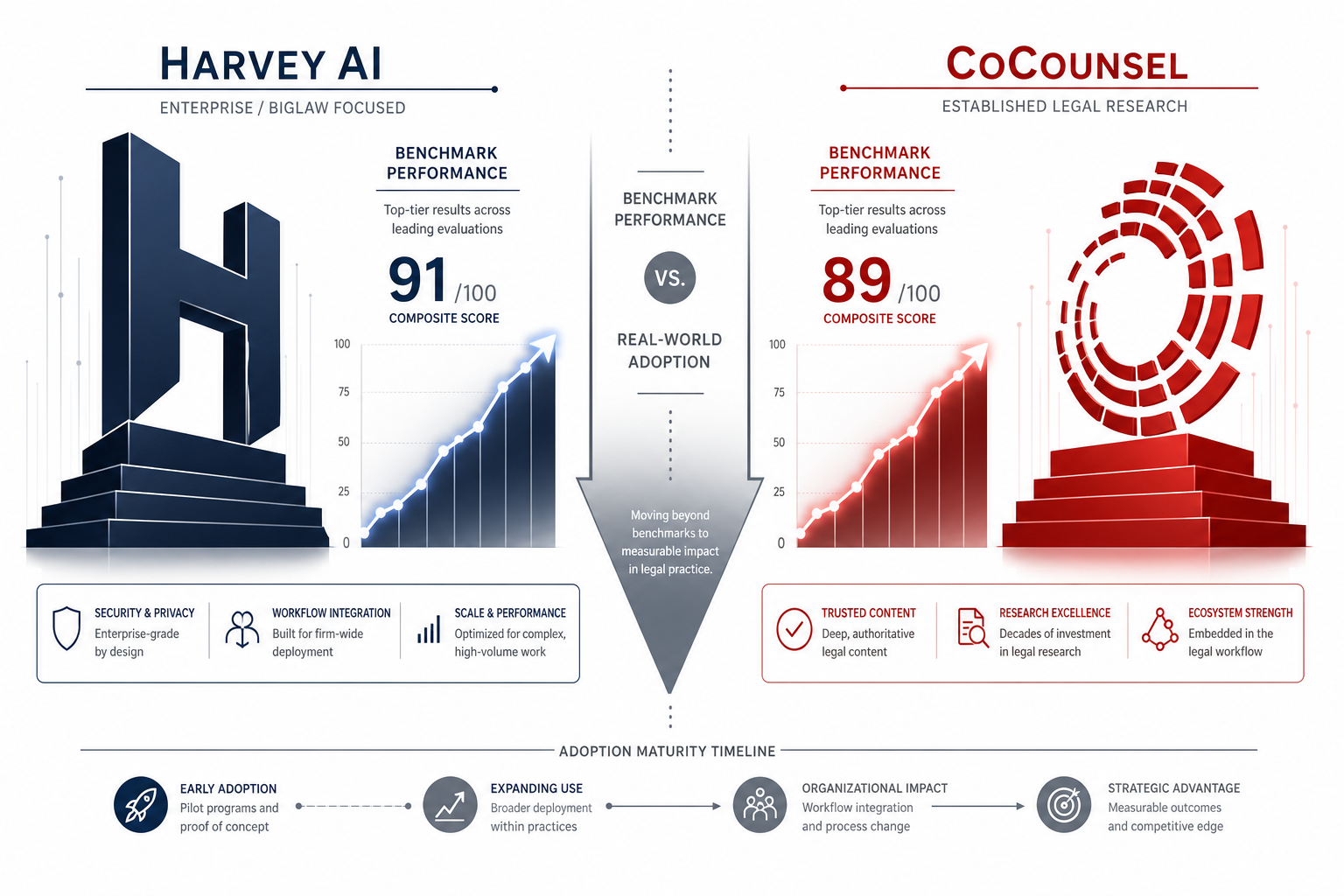
Beyond the Benchmark: Why Harvey AI and CoCounsel Outperform Lawyers in Tests but Lag in Daily Practice
This meta-analysis for law firm innovation directors and technology committees examines the disconnect between top-tier benchmark scores from Harvey and CoCounsel and their ~20% regular adoption rate at large firms, combining Vals AI results with real-world survey data to build a practical evaluation framework.
- Task compared
- Legal research and document analysis benchmark performance vs. real-world adoption
- Audience segment
- Law firm innovation directors, managing partners, and technology committees
- Tools covered
- Harvey AI, CoCounsel
- Evaluation criteria
- Benchmark accuracy, real-world adoption rate, cost and ROI, integration friction, training and change management, professional responsibility compliance
- Last reviewed
- 2026-06-12

Can Free AI Replace Westlaw for Solo Practitioners? A Cost-vs-Risk Analysis
For solo and small-firm attorneys weighing budget against professional responsibility, this article examines whether free general-purpose AI tools (ChatGPT, Claude, Perplexity) can replace paid legal research platforms — with benchmark data, confidentiality risks, and a hybrid workflow strategy.
- Task compared
- Replacing Westlaw or Lexis with free general-purpose AI for legal research
- Audience segment
- solo practitioner and small-firm attorney
- Tools covered
- ChatGPT, Claude, Perplexity, Gemini
- Evaluation criteria
- accuracy, pricing, confidentiality, verification time, bar compliance, citation verification
- Last reviewed
- 2026-06-18

Your Guide to Using ChatGPT for Legal Practice in 2026
This guide explains how legal professionals can safely use ChatGPT in their practice without violating ethics rules or risking sanctions. Drawing on the latest ethics opinions, court rulings, and benchmark data, it outlines the three critical boundaries every lawyer must follow for secure and compliant use.
- Task compared
- Legal research and document drafting using AI
- Audience segment
- Practicing lawyers and law firms
- Tools covered
- ChatGPT, GC AI, CoCounsel, LexisNexis, vLex Vincent AI
- Evaluation criteria
- Accuracy, authoritativeness, data confidentiality, privilege protection, ethics compliance
- Last reviewed
- 2026-07-09

How Reliable Is ChatGPT for Legal Work in 2026?
Benchmark data from Vals AI, GC AI, and Stanford RegLab combined with over 1,600 documented hallucination cases provide an evidence-based answer to where ChatGPT performs reliably and where it still poses risk for legal professionals.
- Task compared
- Legal workflow reliability
- Audience segment
- Legal professionals (small firms, in-house, enterprise)
- Tools covered
- ChatGPT, GC AI, Lexis+ AI, Westlaw AI-Assisted Research
- Evaluation criteria
- Accuracy, hallucination rate, citation reliability, confidentiality, task structure
- Last reviewed
- 2026-07-09

Should Lawyers Use ChatGPT or Specialized Legal AI?
This comparison guide examines whether lawyers can use ChatGPT ethically and safely, evaluating the risks of general-purpose AI against purpose-built legal research tools and providing a framework for compliance with ABA ethics opinions and court requirements.
- Task compared
- Legal research and drafting (with AI)
- Audience segment
- Practicing attorneys (solo to large firm)
- Tools covered
- ChatGPT, Lexis+ AI, Westlaw AI-Assisted Research
- Evaluation criteria
- Accuracy (hallucination rates), confidentiality, source verification, court compliance, pricing, ease of use
- Last reviewed
- 2026-07-09

Claude, ChatGPT, or Kimi K3 — Which Wins for Legal Tasks?
This comparison evaluates Claude, ChatGPT, and the newly launched Kimi K3 on legal-specific criteria including benchmark accuracy, pricing, data privacy, and professional responsibility implications. Find out which model best suits your firm's needs and why a tiered multi-model approach currently outperforms any single-model strategy.
- Task compared
- legal research and analysis
- Audience segment
- law firm
- Tools covered
- Claude, ChatGPT, Kimi K3
- Evaluation criteria
- accuracy, pricing, data privacy, integrations, ease of use, citation reliability, context length
- Last reviewed
- 2026-07-19

How to Evaluate AI Contract Review Tools with Legal-Specific Criteria
This article provides a structured framework for evaluating AI contract review tools using five criteria grounded in professional responsibility obligations, independent benchmark data, enterprise security requirements, implementation realities, and total cost of ownership, enabling legal professionals to build a defensible shortlist and RFP.
- Task compared
- Contract review
- Audience segment
- Legal professionals
- Tools covered
- LegalOn, Harvey, Juro, Kira
- Evaluation criteria
- Citation traceability and verification, Architecture-dependent accuracy, Security and confidentiality posture, Implementation and playbook readiness, Total cost of ownership
- Last reviewed
- 2026-07-09

Free AI Contract Review Tools Compared
This comparison evaluates free and freemium AI contract review tools for solo practitioners and small-firm attorneys, examining accuracy benchmarks, professional responsibility risks, and cost constraints to help you choose a tool that satisfies your obligations.
- Task compared
- Free AI contract review
- Audience segment
- Solo practitioners and small-firm attorneys
- Tools covered
- ChatGPT, Claude, Gemini, Sai, TheLawGPT, Genie AI, goHeather, SpotDraft, Rocket Lawyer, Lawdistrict, ContractCrab
- Evaluation criteria
- Accuracy, pricing, confidentiality, consistency, workflow fit, professional responsibility
- Last reviewed
- 2026-07-09

Free AI for Legal Research: What the Accuracy Benchmarks Actually Reveal About Hallucination Risk
A data-driven analysis of peer-reviewed benchmark studies measuring hallucination rates in free and legal-specific AI tools, designed to help risk-conscious legal professionals match tool choice to task criticality.
- Task compared
- Legal research accuracy and hallucination risk evaluation
- Audience segment
- Risk-conscious legal professionals
- Tools covered
- ChatGPT, Claude, Gemini, Cetient, Lexis+ AI, Westlaw AI-Assisted Research, Alexi, Counsel Stack, Midpage, Vincent AI
- Evaluation criteria
- Hallucination rate, accuracy, authoritativeness, architecture (RAG vs. general-purpose), jurisdictional variability, task complexity
- Last reviewed
- 2026-06-18

Free AI Tools for Lawyers: What Works, What Doesn't, and Where the Risks Are
A professional-responsibility-grounded comparison of free AI tools (ChatGPT, Claude, Gemini, Copilot, and legal-specific platforms) for solo and small-firm attorneys. Evaluates drafting, research, and review capabilities against confidentiality, citation accuracy, and ethical compliance requirements.
- Task compared
- Legal drafting, research, and document review for solo and small-firm attorneys
- Audience segment
- Solo practitioner and small-firm attorney
- Tools covered
- ChatGPT, Claude, Gemini, Copilot, TheLawGPT, LegesGPT, DoNotPay, BriefCatch, Everlaw, CoCounsel
- Evaluation criteria
- Cost, document drafting quality, legal research depth, contract review, citation verification, jurisdiction support, confidentiality guarantees, hallucination risk
- Last reviewed
- 2026-06-14