Full profile
The numbers do not line up because they are not trying to measure the same thing. One legal research AI accuracy benchmark reports Westlaw Precision at 42%. Another leaderboard shows Claude Fable 5 at 88.6%. Stanford’s RegLab found Lexis+ AI hallucinated more than 17% of the time and Westlaw AI-Assisted Research more than 34% of the time. A vendor can still walk into a procurement meeting and say its system is fit for professional legal research, and depending on the workflow being described, that claim may not be nonsense.
That is the uncomfortable part. The spread from 42% to 88.6% is not just marketing fog. It is a warning that “accuracy” has become a container word for different tasks, source environments, model architectures, jurisdictions, and grading rules. Treating those numbers as if they belong on one scoreboard is how a firm ends up buying a tool for the wrong job.

| Headline number | Source | What it is closer to measuring | Why it should not be compared directly |
|---|---|---|---|
| 42% | Stanford RegLab study | Performance in a specific legal research benchmark condition involving Westlaw Precision | It sits inside a study designed around hallucination and answer quality in recognizable legal research systems, not a general model leaderboard. |
| 17%+ hallucination rate | Stanford RegLab study | Lexis+ AI hallucination frequency under tested legal research queries | It measures failure behavior in a research platform, not overall usefulness after lawyer verification. |
| 34%+ hallucination rate | Stanford RegLab study | Westlaw AI-Assisted Research hallucination frequency under tested legal research queries | It reflects the study’s definition of hallucination and tested prompts, not every Westlaw workflow. |
| 88.6% | Vals AI LegalBench leaderboard | A model score on a legal benchmark leaderboard | It is not the same task universe, vendor universe, or workflow as the Stanford platform study. |
Those headline figures come from different benchmark worlds. Stanford’s legal research study and the Vals AI LegalBench leaderboard are both useful, but they answer different procurement questions. One asks, in effect, how often a legal research system gives legally unreliable answers under tested conditions. The other ranks model performance on a benchmark set. A partner may hear both as “accuracy.” A research team has to translate them before anyone signs a contract. [1][2]
The Stanford Numbers Deserve Attention, But Not Overextension
The Stanford RegLab study carries unusual weight because it tested familiar legal research brands, not only general-purpose chatbots or abstract model capabilities. Its reported hallucination rates were not small: Lexis+ AI hallucinated more than 17% of the time, and Westlaw AI-Assisted Research more than 34% of the time, despite vendor messaging around retrieval-augmented legal research and professional-grade source grounding. Stanford HAI summarized the point bluntly: legal AI tools hallucinated in at least one out of six benchmark queries. [1][3]
For a firm, that finding matters less as a brand ranking than as a supervision signal. A one-in-six failure rate is not a reason to ban every AI research tool. It is a reason to stop treating the first generated answer as a draft memo. If a tool is used to find controlling authority, distinguish cases, or answer a jurisdiction-specific question, the workflow has to assume that a plausible answer may still be unsupported, misgrounded, or wrong.
The Stanford work also helps separate legal-native systems from general-purpose systems without pretending that “legal-native” means safe by default. A system connected to legal databases may reduce some risks and introduce better citation pathways, but the benchmark still found meaningful hallucination in tools sold specifically for legal research. That is why the right comparison is not simply general-purpose versus legal-native; it is whether the tool’s tested retrieval, grounding, and answer-generation behavior match the work the firm will assign to it. For a broader discussion of that tool-category distinction, see General-Purpose vs. Legal-Native AI: What Every Lawyer Needs to Know About the Risks.
There is a limit, though. The Stanford results should not be stretched into a permanent product ranking. They are a snapshot from a fast-moving period of legal AI development, and the benchmark’s conditions matter. Model versions change, retrieval systems change, and vendors adjust guardrails after public evaluations. The durable lesson is not that one platform is forever above or below another. It is that even professional legal research systems can fail often enough to require structured verification.
Why Benchmark Scores Fragment So Quickly
Legal research is not one task. A tool can perform well when asked to retrieve a familiar rule and struggle when asked to synthesize conflicting authority across jurisdictions. Another can produce a useful orientation memo but misstate the status of a statute. A third can cite real cases while applying them to a proposition they do not support. Those are different failures, and different benchmarks count them differently.
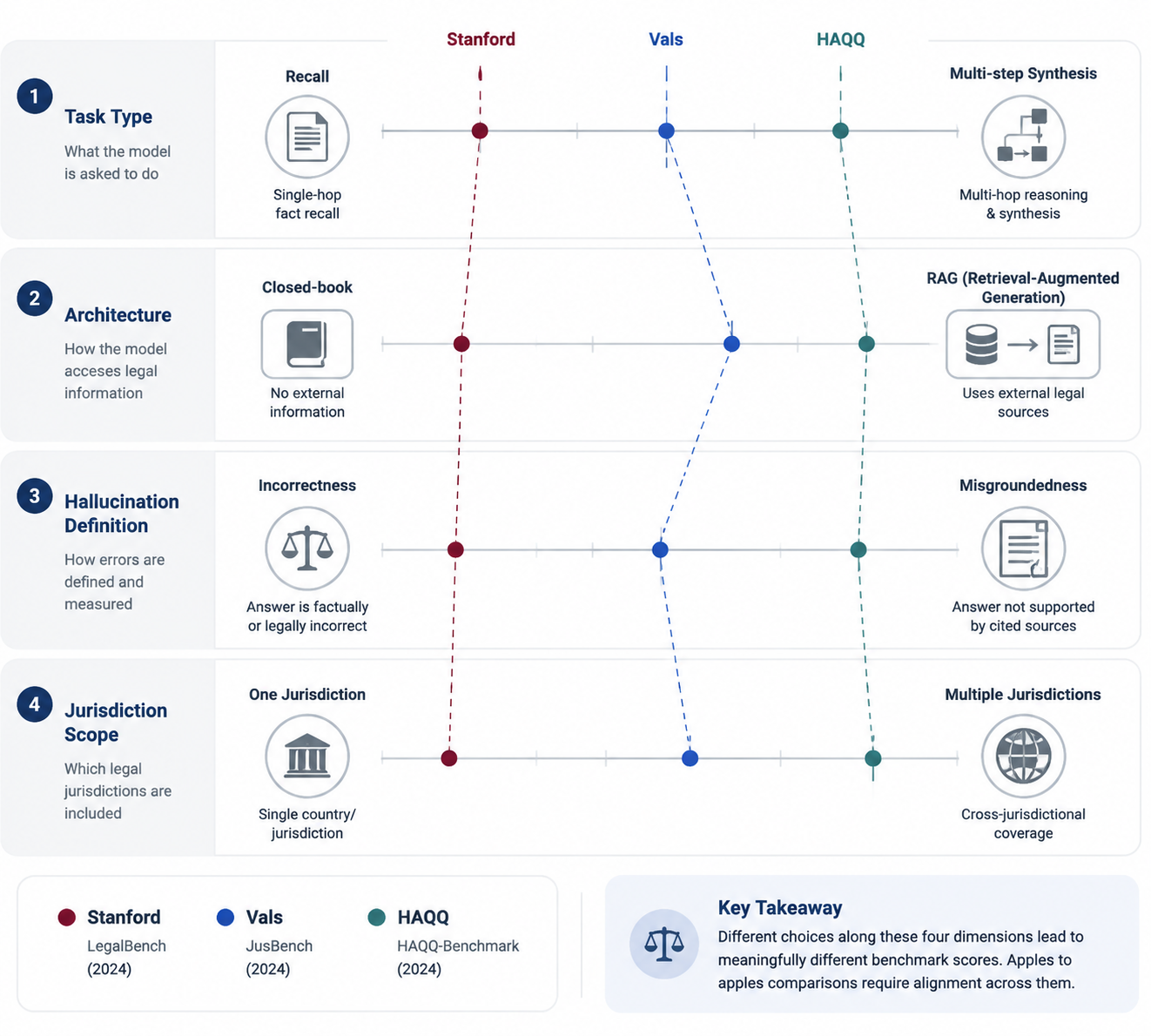
| Benchmark dimension | Procurement question it affects | How it can change the apparent accuracy number |
|---|---|---|
| Task complexity | Will the tool answer simple lookups, multi-step research questions, or both? | Simple recall can produce higher scores than synthesis, issue spotting, or multi-jurisdictional analysis. |
| Architecture | Is the test measuring a closed-book model or a retrieval-augmented legal research system? | A RAG system may be judged on whether retrieved sources support the answer, not just whether the text sounds right. |
| Jurisdiction scope | Does the benchmark cover the jurisdictions where the firm practices? | A strong U.S.-focused result may say little about cross-border research, and vice versa. |
| Hallucination definition | Does the benchmark count only fabricated law, or also unsupported legal application? | A stricter definition can make a system look worse while giving a more useful picture of review burden. |
| Vendor participation | Are the tools the firm actually uses included? | A clean leaderboard may exclude the platforms most relevant to the buyer. |
The hallucination definition alone can move the conversation. Stanford’s “Hallucination-Free?” work distinguishes incorrectness from misgroundedness: an answer may cite a real source but rely on it for a claim it does not actually support. That distinction is particularly important in legal research, where a fabricated citation and an overread citation create different review tasks but can both mislead a lawyer. AI Law Librarians’ synthesis of the science emphasizes these methodological differences when comparing legal hallucination studies. [1][4]
This is also where many public discussions become too casual with leaderboards. A high score on a legal benchmark can be meaningful evidence that a model handles a defined test set well. It does not automatically prove that the model will handle a firm’s recurring research questions, internal precedent, preferred sources, state-law coverage, or verification protocol. The benchmark may be testing a useful skill. It may simply not be the skill the firm is buying.
What Vals Adds, And What Its Vendor Gap Leaves Unanswered
Vals AI is valuable because it pushes the market toward more structured, independent legal AI evaluation. Its LegalBench leaderboard gives buyers a visible comparison point, and its VLAIR-Legal Research work attempts a broader head-to-head evaluation of legal research performance. But the VLAIR study has a procurement problem built into the evidence base: major legal research vendors, including Thomson Reuters, LexisNexis, and vLex, opted out. [5]
That opt-out matters. A law firm deciding whether to expand Westlaw, Lexis, vLex, a general-purpose model, or a specialist AI tool cannot use an otherwise sophisticated comparison as a complete market map if the most widely used legal research platforms are absent. The absence does not make the study useless. It changes what the study can prove.
- Use Vals-style results to understand how benchmark designers are separating legal task types and measuring model performance.
- Do not use a leaderboard that excludes a relevant vendor as proof that the excluded vendor is better or worse.
- Ask vendors that opted out to provide equivalent task-level validation, not a general assurance that their platform is different.
- Treat participation itself as a diligence question: if a vendor declines independent testing, the firm needs a replacement validation plan.
The tool-specific observations across the cited materials are still useful when kept narrow. Lexis+ AI appears stronger on complex multi-jurisdictional queries, Westlaw shows stronger statutory and regulatory coverage, ChatGPT offers breadth with higher hallucination risk, and Harvey shows strength in firm-specific knowledge integration through Harvey LAB materials. Those are not universal product verdicts. They are clues about where to design follow-up testing. [5][6]
The HAQQ Study Is A Reminder That Correctness Is Not The Only Cost
HAQQ’s benchmark deserves a different kind of caution. It is vendor-published, so it should not be treated as neutral market adjudication. At the same time, the reported methodology is more useful than many marketing claims: the study describes a 3,000-answer evaluation, published prompts, open data, and temperature 0. Its headline finding is severe enough to matter even with the vendor caveat: 24% of frontier-model legal answers cited or applied law that did not support the claim, and every tested model, including leaders, fabricated at least one citation. [7]
The procurement lesson from HAQQ is not only about hallucination. It also reports a 90× cost range, from $0.0009 to $0.082 per task, and a 17× speed range, from 7.7 seconds to 134 seconds. Those figures should not override legal quality, but they do affect deployment. A tool used for occasional specialist research can tolerate a different latency and cost profile than a tool placed in front of a litigation team that runs hundreds of first-pass queries a week. [7]
Cost and speed are where benchmark conversations often become oddly unrealistic. The “best” answer in a lab may not be the best system for a practice group if it is too slow for the intake workflow, too expensive at expected volume, or too difficult to verify. Conversely, a cheap fast answer that creates heavy attorney review time is not cheap. The unit cost that matters is the cost of a usable, verified answer.
Workflow Benchmarks Are Self-Interested, But Not Irrelevant
Thomson Reuters has argued that measuring initial AI answer accuracy alone is like measuring highway speed to determine door-to-door travel time. Its position is that firms should evaluate legal AI in an end-to-end workflow, including verification, where differences between tools may narrow after a lawyer checks the answer against sources. That argument appears in a vendor opinion piece, not a peer-reviewed study, and it naturally favors an ecosystem built around Westlaw research and verification tools. [8]
Still, the workflow point should not be dismissed just because it is convenient for the vendor making it. Lawyers do not file raw benchmark answers. They review cited authority, check currentness, compare jurisdictions, and decide whether the output can survive use in a client memo, brief, or negotiation. If the firm’s actual process includes mandatory source review, the relevant metric is not only first-answer accuracy. It is accuracy after the firm’s verification workflow, plus the time and expertise required to get there.
That distinction can cut both ways. A tool with a weaker first answer may be acceptable if it reliably surfaces the right sources and makes attorney review faster. A tool with a polished first answer may be dangerous if it hides weak grounding behind confident prose. The benchmark that matters is the one that lets the firm predict review burden, not merely admire fluency.
Risk Flagging Is A Different Capability From Answering Correctly
Legalbenchmarks.ai Phase 2 adds another dimension: whether systems identify risk in their own or others’ outputs. It found specialized legal AI tools flagged risks in 83% of high-risk outputs, compared with 55% for general AI. It also reported that only 6% of surveyed lawyers required 100% accuracy to trust AI output, while 55% were comfortable below 90%. [9]
Those two findings should be kept separate. The first is about a tool capability: risk detection. The second is about lawyer attitudes toward trust thresholds. Neither means lawyers should accept wrong answers. The more useful point is that many lawyers already understand legal AI as a supervised tool rather than an autonomous authority. Procurement should therefore ask not only, “How often is it right?” but also, “How well does it expose uncertainty, missing authority, jurisdictional limits, and verification needs?”
This connects directly to professional responsibility, because benchmark interpretation is not an academic exercise once lawyers rely on output in client work. For a fuller governance discussion, see Limits and Liabilities: A Professional Responsibility Framework for AI Contract Review in 2026. For enforcement context around hallucinated legal authorities, see AI Hallucinations in Legal Practice: The Sanctions Trajectory and the Verification Discipline Every Lawyer Must Adopt.
A Practical Way To Read Any Legal AI Accuracy Benchmark
Before comparing vendors, write down the research work the firm actually wants the tool to perform. This sounds obvious, but it is the step most often skipped. “Legal research” could mean checking whether a case is still good law, finding state-specific statutory authority, summarizing a body of cases, comparing rules across jurisdictions, drafting a research memo, mining internal work product, or giving a junior associate a starting point. Those are not interchangeable benchmark tasks.
| Firm research need | Closest benchmark evidence to seek | Evidence to discount |
|---|---|---|
| Fast orientation on unfamiliar legal issues | Benchmarks testing breadth, issue spotting, and clear uncertainty signals | Scores limited to narrow factual recall. |
| Controlling-law research in a specific jurisdiction | Benchmarks with jurisdiction-specific source coverage and grounded citation review | Multi-national or general legal benchmarks that do not report jurisdiction performance. |
| Multi-jurisdictional comparison | Tests involving synthesis across jurisdictions and conflict handling | Single-jurisdiction studies presented as general research accuracy. |
| Statutory or regulatory research | Evidence on code, regulation, currentness, and source retrieval quality | Case-law-heavy benchmarks used as a proxy for all legal research. |
| Use with firm knowledge or prior work product | Validation involving internal-document retrieval, permissions, and firm-specific grounding | Public-law benchmarks that never test private knowledge integration. |
| High-volume first-pass research | Accuracy plus cost, speed, and review-time data | Pure quality rankings that ignore latency and unit economics. |
A firm evaluating free or low-cost systems has an additional reason to be disciplined about benchmark fit: those tools may be easier to test quickly but harder to govern consistently across practice groups. For a risk-tiered comparison built around similar benchmark concerns, see Best Free AI for Legal Research: A Risk-Tiered Comparison for Attorneys.
The questions procurement should ask after seeing a benchmark
- What exact task was tested: recall, retrieval, synthesis, drafting, risk spotting, or verification support?
- Was the system closed-book, connected to a legal database, or connected to firm-specific materials?
- Which jurisdictions and source types were included, and are they the jurisdictions and sources the firm uses?
- How did the benchmark define hallucination: fabricated source, wrong answer, unsupported proposition, or misgrounded citation?
- Were the firm’s candidate vendors included, excluded, or allowed to decline participation?
- Was the score measured before or after a realistic lawyer verification workflow?
The last question is often the most revealing. If a vendor reports only initial answer quality, ask for a validation exercise that includes source checking. If a vendor reports only workflow-adjusted performance, ask to see the raw failure modes before verification. A buyer needs both: the first answer tells you what risk enters the system, and the verified answer tells you what risk remains after the firm spends professional time.
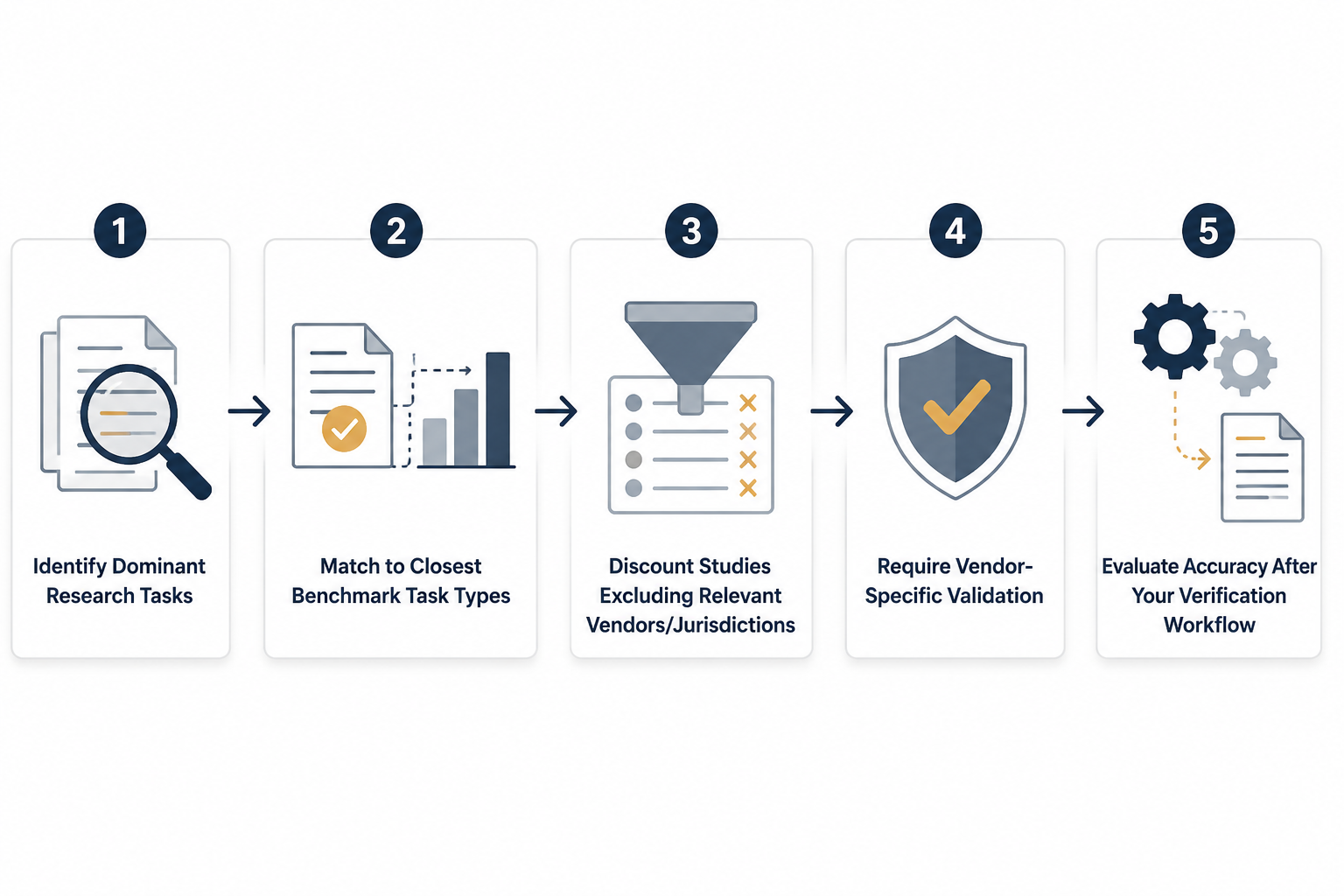
How To Turn Benchmark Conflict Into A Procurement Map
A usable procurement process does not begin with the highest public score. It begins with the firm’s dominant research tasks, then maps outward to the closest benchmark conditions. A litigation group that needs controlling state authority should not give much weight to a benchmark that rewards broad national synthesis without jurisdiction-specific grading. A transactions team using AI for contract-adjacent legal research should not rely on a case-law hallucination score alone. A knowledge team evaluating firm-specific retrieval should ask for evidence that internal materials, permissions, and grounding were actually tested.
- Identify the firm’s dominant research tasks and rank them by risk, frequency, and review burden.
- Match each task to the closest public benchmark type, rather than to the highest overall score.
- Discount studies that exclude relevant vendors, jurisdictions, source types, or workflow steps.
- Require vendor-specific validation where public evidence is missing, especially for platforms that opted out of independent comparisons.
- Evaluate accuracy after the firm’s actual verification workflow, including who checks sources, how long review takes, and what errors survive.
This approach will not produce a clean universal winner, and that is a feature rather than a defect. The benchmark landscape through Q3 2026 is too fragmented for a single legal research AI accuracy number to carry a procurement decision. Stanford is strongest as an independent warning about hallucination in recognizable legal research systems. Vals is useful for structured task comparison, with a serious participation gap for major platforms. HAQQ adds cost, speed, and unsupported-law findings, with the caveat that it is vendor-published. Thomson Reuters’ workflow argument is self-interested but directionally important because lawyers do not use unverified answers in isolation.
The most trustworthy number is not the highest number. It is the number whose test conditions most closely resemble the work, sources, jurisdiction, and review burden the firm will actually own.
References
- Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools, Journal of Empirical Legal Studies, 2025, https://doi.org/10.1111/jels.12413
- LegalBench Leaderboard, Vals AI, https://vals.ai/benchmarks/legal_bench
- AI on Trial: Legal Models Hallucinate in 1 Out of 6 or More Benchmarking Queries, Stanford HAI, https://hai.stanford.edu/news/ai-trial-legal-models-hallucinate-1-out-6-or-more-benchmarking-queries
- What the Science Says About Hallucinations in Legal Research, AI Law Librarians, 2026-02-19, https://www.ailawlibrarians.com/2026/02/19/what-the-science-says-about-hallucinations-in-legal-research/
- VLAIR Legal Research Report, Vals AI, 2025-10, https://www.vals.ai/industry-reports/vlair-10-14-25
- Introducing Harvey’s Legal Agent Benchmark, Harvey, https://www.harvey.ai/blog/introducing-harveys-legal-agent-benchmark
- Best AI for Legal Work Benchmark, HAQQ AI, https://haqq.ai/blog/best-ai-for-legal-work-benchmark
- Best Practices for Benchmarking AI for Legal Research, Thomson Reuters, https://www.thomsonreuters.com/en-us/posts/innovation/thomson-reuters-best-practices-for-benchmarking-ai-for-legal-research/
- Phase 2 Research, Legalbenchmarks.ai, https://www.legalbenchmarks.ai/research/phase-2-research
Comments
Join the discussion with an anonymous comment.