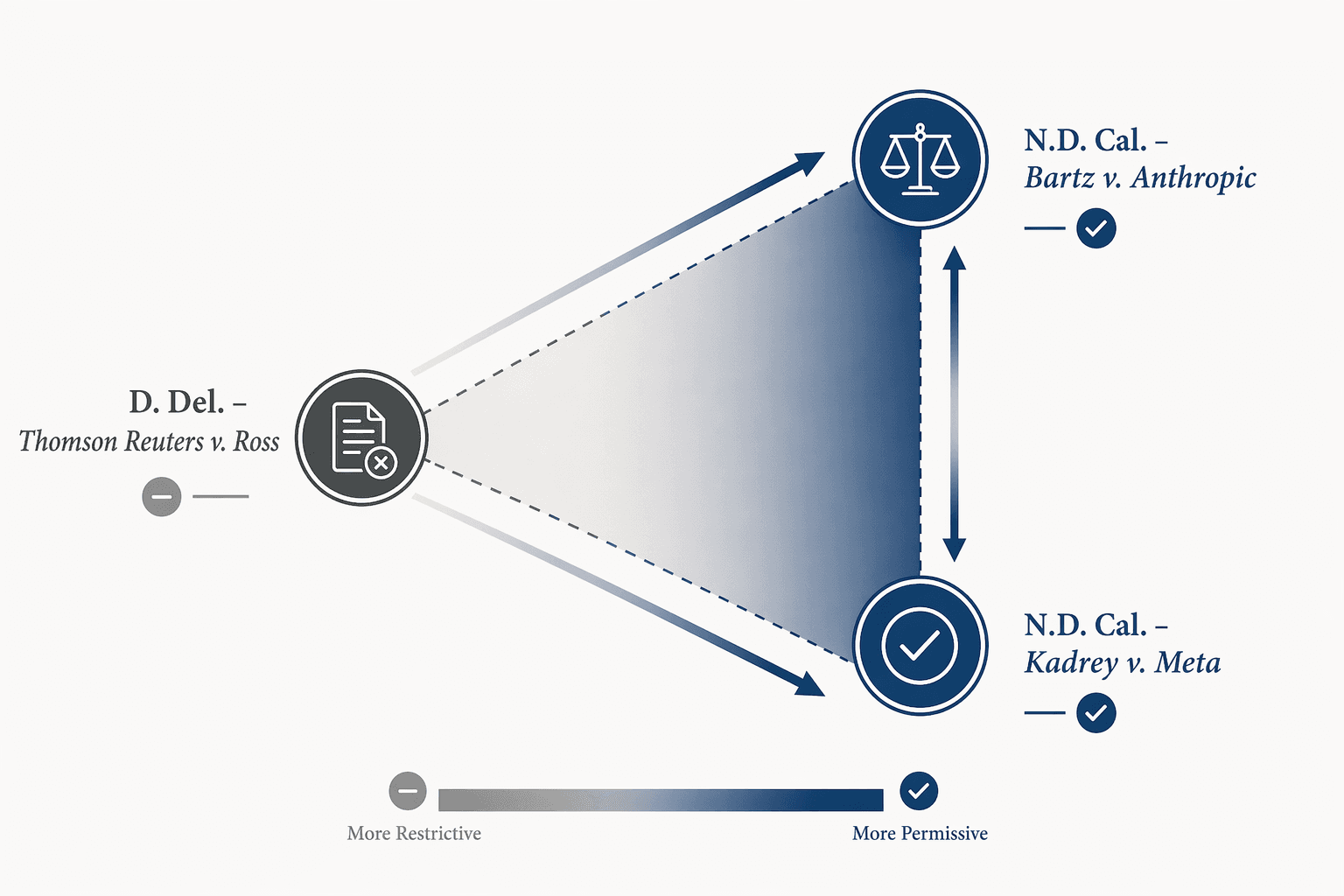
Introduction: The Fair Use Triangle Takes Shape
For in-house IP counsel and AI product attorneys, 2025 was the year fair use doctrine went from academic abstraction to boardroom liability driver. Three rulings from two federal district courts produced outcomes that cannot be reconciled by a single rule. Instead, they form a triangle whose vertices are defined by jurisdiction, AI architecture, and the provenance of training data.
In February, the District of Delaware ruled that scraping Westlaw headnotes to build a competing legal research platform was not fair use — a decision that now heads to the Third Circuit. Four months later, the Northern District of California produced two rulings within 48 hours: training a large language model on lawfully acquired books was spectacularly transformative, but storing pirated copies of those same books in a training repository was not. The same judge then found Meta's training on a separate book corpus to be fair use — while explicitly inviting a future plaintiff to bring a better case on market harm.
This article provides a comparative doctrinal analysis of these three rulings. For aggregate case volume data — total filings by year, venue concentration, and defendant exposure — see our companion piece, AI Litigation by the Numbers. Here, we focus on the doctrinal tensions that will define the next wave of AI copyright litigation.
Thomson Reuters v. Ross: Non-Generative AI, Copyright Owner Wins
On February 11, 2025, Judge Stephanos Bibas of the District of Delaware granted partial summary judgment to Thomson Reuters in its case against Ross Intelligence. The ruling addressed two distinct questions: whether Westlaw headnotes are copyrightable, and whether Ross's use of those headnotes to train a legal research AI was fair use. The court answered yes to the first and no to the second.
The copyrightability holding is significant but narrow. The court found that Westlaw's headnotes — short summaries of legal points written by attorney-editors — contained sufficient originality to qualify for protection. This is consistent with decades of precedent holding that editorial summaries and annotations can be copyrightable even when the underlying judicial opinions are not.
The fair use analysis is where the ruling becomes an outlier. The court weighed all four statutory factors and found each tilted against Ross. The use was commercial, the headnotes were used to build a direct competitor product, and the transformation was minimal — Ross's AI did not create new expression but rather replicated the legal analysis embedded in the headnotes. Market harm was clear: Ross aimed to displace Westlaw itself.
The key distinction from the California cases is that Ross involved a non-generative, search-based AI. The AI did not produce new text; it retrieved and re-presented legal analysis derived from the copyrighted headnotes. This matters because the transformative-use argument is weaker when the AI's output is functionally substitutable for the original work — a distinction that may prove durable as courts grapple with different AI architectures.
Bartz v. Anthropic: Generative Training Lawful, Piracy Is Not
On June 23, 2025, Judge William Alsup of the Northern District of California issued a ruling that simultaneously validated and constrained generative AI training. The case, brought by a class of authors including comedian Sarah Silverman and novelist Christopher Farnsworth, challenged Anthropic's use of copyrighted books to train its Claude model.
The court drew a sharp line between two categories of training data. For books that Anthropic acquired lawfully — through licensed databases, publisher agreements, or other legitimate channels — the court found training to be transformative — spectacularly so. The reasoning tracks the core logic of the Google Books and HathiTrust decisions: the purpose of training is to extract patterns and linguistic structures, not to reproduce the original expression. The resulting model does not substitute for the copyrighted works.
But the court drew a hard line at pirated copies. Anthropic had downloaded approximately 482,460 books from a repository it knew contained unauthorized copies. The court found that storing these pirated files in a central library for training purposes was infringing, even if the training itself might have been fair use had the copies been lawfully acquired.
The case settled shortly after the ruling for $1.5 billion, with an estimated payout of approximately $3,000 per work. The settlement avoided further litigation on the scope of damages and the extent of Anthropic's exposure for the pirated copies. Attorneys have since requested $300 million in fees — 20% of the settlement fund — which could affect the final per-work distribution.
Kadrey v. Meta: Fair Use for Training, But the Judge Left a Roadmap
Two days after Bartz, on June 25, 2025, Judge Alsup issued a second fair use ruling — this time in a case brought by author Richard Kadrey and others against Meta. The plaintiffs alleged that Meta's training of its LLaMA models on a corpus of copyrighted books infringed their rights.
The court again found training to be highly transformative and fair use on the record presented. The reasoning mirrored Bartz: extracting patterns from text to build a language model serves a fundamentally different purpose from reproducing the text itself. The court granted partial dismissal of the copyright claims.
But the ruling is notable for what it left open. Judge Alsup explicitly criticized the plaintiffs' half-hearted market-harm arguments, noting that they had failed to present evidence that Meta's training had caused or would cause market displacement. More importantly, the judge stated that a different outcome might be warranted on a stronger factual record — particularly if plaintiffs could show that a functioning licensing market exists and that the defendant's training undermined it.
The Kadrey ruling also underscores a critical procedural point: the absence of piracy allegations. Unlike Anthropic in Bartz, Meta's training data acquisition was not challenged as involving pirated sources. This distinction may explain why Meta received a cleaner fair use finding — and why the next wave of cases will focus intensely on how defendants acquired their training data.
The Fair Use Triangle: Delaware Skepticism vs. Northern California Openness
Taken together, the three rulings form a triangle whose dimensions are defined by jurisdiction, AI type, and data provenance. The table below maps the key doctrinal tensions.
| Dimension | Thomson Reuters v. Ross | Bartz v. Anthropic | Kadrey v. Meta |
|---|---|---|---|
| Jurisdiction | D. Del. | N.D. Cal. | N.D. Cal. |
| AI Type | Non-generative (search-based) | Generative (LLM) | Generative (LLM) |
| Training Data Source | Scraped proprietary headnotes | Lawful + pirated books | Lawful books (no piracy alleged) |
| Transformation Finding | Minimal — direct competitor | Spectacularly transformative | Highly transformative |
| Market Harm Analysis | Strong — product displacement | Weak — no substitution found | Weak — plaintiffs failed to prove |
| Outcome | Fair use rejected | Training fair use; piracy infringing | Training fair use (with roadmap) |
| Current Status | Appeal to Third Circuit | Settled for $1.5B | Dismissal granted; appeal possible |
The jurisdictional divide is the most visible tension. Delaware's skepticism toward fair use for AI training — at least in the non-generative context — contrasts sharply with Northern California's embrace of the transformative-use rationale. If the Third Circuit affirms Thomson Reuters, the circuit split will be formalized, and the Supreme Court will face pressure to resolve it.
The AI-type distinction is equally important. The transformative-use argument is strongest when the AI generates new text rather than retrieving and re-presenting existing expression. Non-generative AIs that function as search or retrieval tools may face a harder fair use path — a distinction that will matter as courts evaluate AI tools in legal research, medical diagnosis, and other professional contexts.
The Piracy Variable: Why Acquisition Channel Now Splits Outcomes
The single clearest doctrinal signal from the 2025 rulings is that the acquisition channel of training data now determines outcomes. Lawful acquisition leads to transformative fair use; pirated sources lead to infringement. This is not a subtle distinction — it is the difference between a $1.5 billion settlement and a clean dismissal.
The practical implications for AI developers are straightforward but operationally demanding:
- Build a documented data-provenance strategy that traces every training source to its origin and confirms lawful acquisition.
- Wall off dubious sources — pirated book repositories, scraped databases with ambiguous terms of use, and any dataset whose provenance cannot be verified.
- Audit existing training data for pirated content. The Bartz ruling makes clear that even if training itself is fair use, the act of storing unauthorized copies creates independent infringement exposure.
- Maintain separate repositories for lawfully acquired and potentially problematic data. The court in Bartz drew a bright line between the two categories.
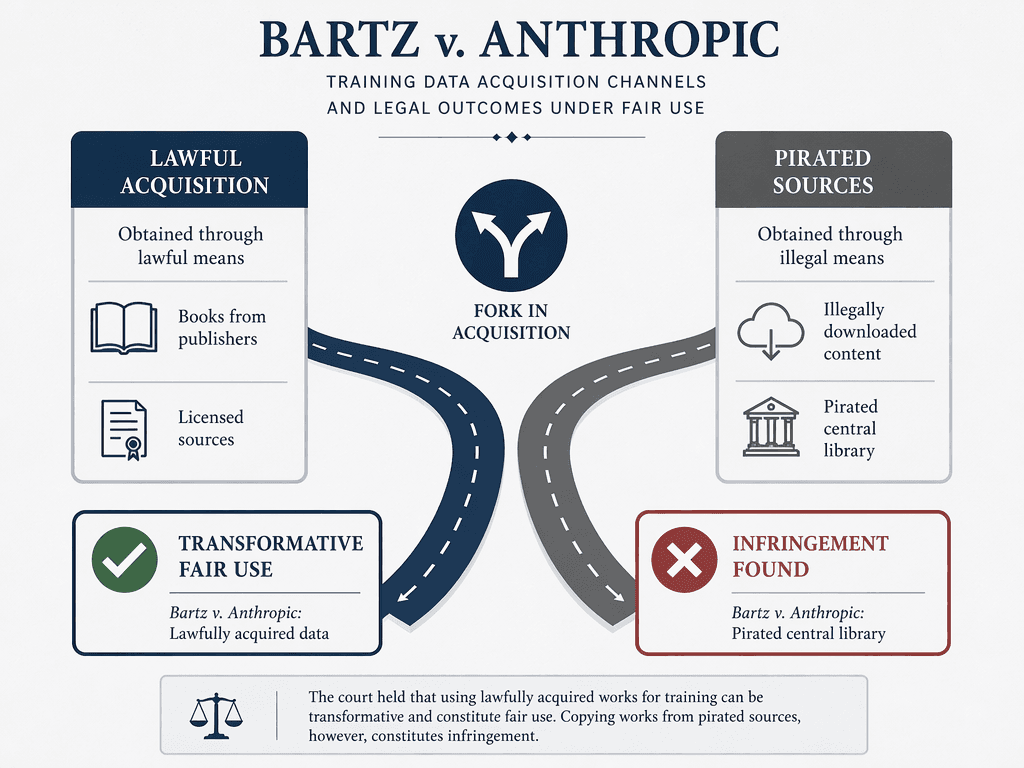
The contrast between Bartz and Kadrey is instructive. In Bartz, Anthropic's use of pirated books created a $1.5 billion liability even though the court found the training itself to be transformative fair use. In Kadrey, Meta faced no similar allegation, and the court's fair use finding was correspondingly cleaner. The lesson is clear: data provenance is not just a compliance issue — it is the primary determinant of litigation risk.
The Licensing Market Signal: Disney-OpenAI, UMG/WMG-Udio, and Factor Four
Fair use factor four — the effect of the use on the potential market for or value of the copyrighted work — has historically been the most important factor in AI training cases. The 2025 rulings suggest that a functioning licensing market could shift the analysis against fair use in future cases.
Two developments in 2025 signal that such a market is emerging. First, Disney and OpenAI signed a $1 billion, three-year licensing deal granting OpenAI access to over 200 Disney characters for its Sora video generation model. Second, Universal Music Group and Warner Music Group settled with AI music generators Udio and Suno, entering into licensing arrangements rather than continuing litigation.
The significance for factor four analysis is straightforward. In Kadrey, the plaintiffs failed to present evidence of a functioning licensing market, and the court noted this gap explicitly. If future plaintiffs can show that licensing markets exist — and that the defendant chose to train on unlicensed data rather than pay market rates — the market-harm factor could tip against fair use.
For in-house IP counsel, the licensing market signal creates both opportunity and risk. Companies developing AI models should evaluate whether licensing is available for their training data categories — and whether the cost of licensing is lower than the expected cost of litigation. Companies owning valuable content should consider whether to enter the licensing market or to hold out for litigation outcomes that might establish stronger copyright protections.
What to Watch in 2026: OpenAI MDL Discovery, Getty v. Stability, and the Thomson Reuters Appeal
The 2025 rulings set the stage for a pivotal 2026. Several developments merit close attention from in-house IP counsel and AI product attorneys.
- In Re OpenAI MDL (S.D.N.Y.): The court has ordered production of 78 million ChatGPT output logs through January 2026, following an earlier order for 20 million logs. Discovery in this multidistrict litigation could reveal the extent to which OpenAI's models reproduce copyrighted expression — and whether the company's training data included pirated sources.
- Getty v. Stability AI: This case, involving Stability AI's training on Getty Images' copyrighted photographs, is the next major training case to watch. The outcome could clarify whether visual AI models receive the same transformative-use treatment as text-based LLMs.
- Thomson Reuters v. Ross Appeal: The Third Circuit's decision will determine whether the Delaware skepticism toward AI fair use survives appellate review. A circuit split with the Ninth Circuit would dramatically increase the likelihood of Supreme Court review.
- Thaler v. Perlmutter: The Supreme Court denied certiorari on March 2, 2026, reaffirming that human authorship is a bedrock requirement of US copyright law. This ruling does not directly affect fair use analysis, but it reinforces that AI-generated works cannot be copyrighted — a constraint that shapes the incentives for both plaintiffs and defendants.
- Expected rulings in OpenAI and Google training cases: Courts are expected to decide AI training cases involving OpenAI and Google in 2026. These decisions will test whether the Bartz/Kadrey framework extends to other defendants and other training datasets.
For readers seeking a broader regulatory compliance perspective alongside these litigation watchpoints, see our companion article, AI Compliance in 2026: Mapping the EU AI Act High-Risk Deadline, U.S. State Law Patchwork, and Federal Preemption Battle. And for in-house IP counsel evaluating internal use of generative AI tools, ChatGPT for Legal Work: The Complete Ethics and Risk Framework for Attorneys in 2026 provides a practical framework for understanding the evolving fair use landscape before deploying such tools.
Comments
Join the discussion with an anonymous comment.