Full profile
The familiar “94% accuracy” figure is not a myth. It comes from a real NDA review benchmark in which LawGeex reported that its AI achieved 94% accuracy against 85% for human lawyers, using F1 scoring across a defined set of NDA review issues.[1] That is a meaningful result for anyone who has watched lawyers spend expensive time finding routine NDA problems under deadline pressure.
It is also a narrow result. The study tested NDAs, not every contract type. It measured performance against a defined issue set, not open-ended risk judgment. F1 scoring balances precision and recall; it does not tell a general counsel which missed clause is tolerable, which false alarm will slow a deal, or whether the system can recognize that an expected protection is absent. The number is useful as a starting signal. It is not a portable warranty of contract-review competence.
That distinction matters because AI contract analysis accuracy risks rarely show up as one clean failure rate. They show up as a distribution: a missed non-compete carveout here, a wrongly flagged indemnity threshold there, a hallucinated explanation when the model sees an unfamiliar agreement structure, or an over-literal answer that ignores how a deal point works across several provisions. The deployment question is not “Can AI review contracts?” It is “Which contract, which task, which architecture, and what verification layer?”
The 94% Benchmark Still Matters, Just Not the Way It Is Usually Quoted
The LawGeex benchmark became durable because it answered a real operational question: could a contract AI system identify common NDA issues at a level comparable to trained lawyers? In that setting, the reported answer was yes. The AI reviewed the agreements faster and scored higher than the participating lawyers on the benchmark’s chosen metric.[1]
For legal operations, that is not trivial. NDA review is a good candidate for structured automation because the agreement type is familiar, the issue set can be standardized, and many deviations are repeatable. If a company has a high-volume NDA queue and a settled playbook, a tool that performs well on comparable documents can reduce first-pass review burden.
The problem begins when the same figure is treated as if it answers questions the benchmark did not ask. A system that performs strongly on NDA issue spotting has not thereby proven that it can review a complex services agreement, identify every embedded commercial threshold, infer missing obligations, rank negotiation risk, or propose fallback language consistent with business policy. Those are adjacent legal operations tasks, but they are not the same task.
This is the first practical lesson from the benchmark record: accuracy claims need a task label. “94% accurate” is materially different if it means clause extraction on standardized NDAs, deal-point identification in mixed commercial contracts, or open-ended advice about whether a provision should be accepted.
Accuracy Splits Along Task Lines
Contract analysis work is often described as if it were one activity. In practice, the difficulty changes sharply depending on what the tool is being asked to do.
| Task | What the tool must do | Main accuracy risk |
|---|---|---|
| Clause extraction | Find and classify known clause types | Missing a clause or mislabeling a familiar provision |
| Absence checks | Confirm that an expected clause or protection is not present | Treating silence as proof too quickly, or missing language that appears in an unusual location |
| Deal-point identification | Extract thresholds, exceptions, dates, caps, conditions, and party-specific obligations | Over-literal reading or failure to connect related provisions |
| Risk assessment | Map language to a legal or business risk position | Applying the wrong policy, weighting the wrong issue, or overstating confidence |
| Negotiation guidance | Recommend revisions or fallback positions | Inventing rationales, ignoring business context, or producing advice that sounds complete but is not verified |
The evidence becomes more useful once it is read through this task split. Harvey’s 2025 Contract Intelligence Benchmark reported that out-of-the-box large language models identified only 65% to 70% of valid deal points, while specialized agents approached human-level performance. The same benchmark also described “over-literal interpretation” as a distinct failure mode and found that lawyer-plus-AI combinations outperformed either lawyers or AI alone by more than 5%.[2]
That is a deployment clue, not a victory lap. The finding suggests that the safer operating model is often not full substitution, but structured collaboration: let the system pre-read, extract, compare, and surface issues; require a lawyer or trained contract reviewer to verify the outputs that carry legal or commercial consequence. The value is in narrowing the review surface, not in pretending the surface disappeared.
LegalOn’s 2026 benchmark points in the same direction from another angle. LegalOn reported that its purpose-built contract review system defeated 11 general-purpose models across 3,282 contracts, with a 17x speed advantage and stronger accuracy on every provision type tested. The benchmark also identified weak points for general AI on clause identification, thresholds, multi-part requirements, and absence checks.[3]
Because Harvey and LegalOn published their own benchmarks, they should not be read as neutral third-party validation. They are still useful because they describe failure patterns that match how contract review actually breaks: not usually through spectacular nonsense, but through a confident answer to the wrong sub-question.
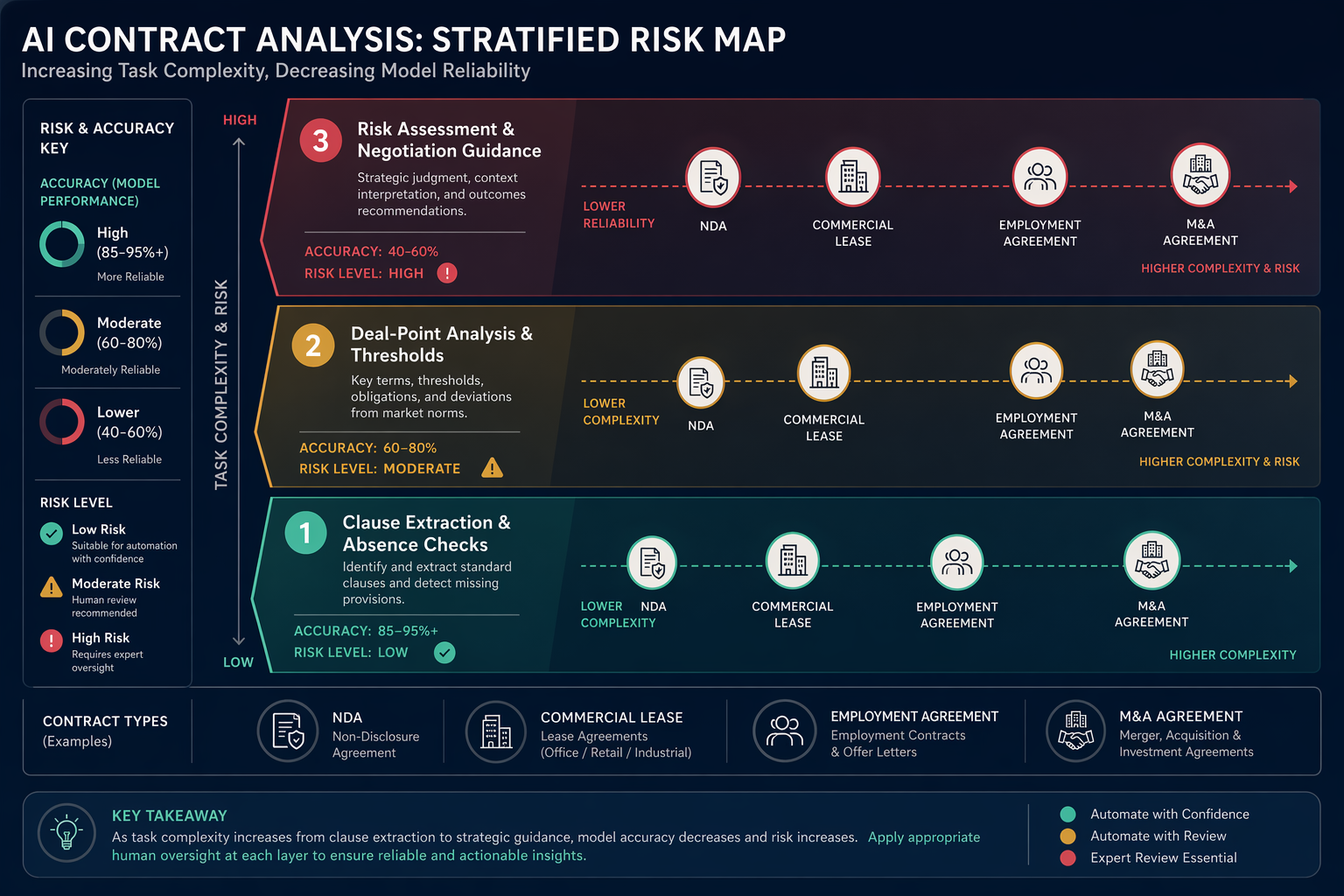
Purpose-Built Systems and General-Purpose LLMs Are Not Interchangeable
A general-purpose LLM can summarize a contract impressively. That does not make it a contract analysis system. The benchmark record increasingly separates systems designed around contract tasks from models that are merely capable of reading contract text.
A purpose-built contract tool may include clause taxonomies, issue models, retrieval, document segmentation, playbook logic, redline workflows, and controls for source-grounding. A general-purpose model may have strong language ability but lack the architecture needed to ask, for example, whether a limitation-of-liability cap has a carveout, whether that carveout is reciprocal, whether the indemnity provision imports a separate standard, and whether the customer’s playbook treats that combination as acceptable.
LegalOn’s reported results are especially relevant here because the benchmark did not merely say one model was “better.” It identified categories where general AI struggled: clause identification, thresholds, multi-part requirements, and absence checks.[3] Those are exactly the places where contract risk is often embedded. A missed threshold is not a stylistic error. A mishandled absence check can produce the false comfort that a document contains a protection it does not.
Harvey’s benchmark also pushes against treating model choice as the whole story. Its distinction between out-of-the-box LLM performance and specialized agents suggests that workflow design, decomposition of legal tasks, and verification methods can change outcomes materially.[2] In other words, “Which model?” is usually an incomplete procurement question. “How is the model constrained, instructed, grounded, evaluated, and checked?” is closer to the operational issue.
For readers who want the technical side of that distinction, the deeper question is architecture, not branding. A separate discussion of AI contract review software architecture is the natural next stop after the benchmark evidence.
The Hidden Cost of a High Average: False Negatives, False Positives, and Hallucinations
An average accuracy number can hide three very different risk events.
- A false negative means the system misses a real issue. In contract review, this is often the most dangerous failure because the document may proceed without anyone knowing review failed.
- A false positive means the system flags an issue that is not actually a problem. This may be less dangerous legally, but it can erode trust, slow deal velocity, and train users to ignore alerts.
- A hallucination means the system invents or misstates something about the document, law, or reasoning. In contract workflows, this risk becomes more serious when the output moves from extraction to explanation or recommendation.
Helium42 reports industry figures of 94% to 98% accuracy on standardized contracts, with 2% to 3% false negatives, 5% to 8% false positives, and 5% to 12% hallucination risk for LLM-based tools on novel contract types.[4] Those figures are useful as a risk vocabulary, but they should be handled carefully: Helium42 attributes them to industry data and indirectly cited Gartner and Deloitte material, not to primary studies independently verified here.
Even with that caveat, the shape of the risk is plausible. Standardized contracts are easier because the model has seen similar structures and the reviewer can define the expected issue set. Novel contract types are harder because the tool must decide what matters without the same pattern support. A system that performs well on recurring NDAs or vendor forms may still be unreliable on a one-off strategic alliance agreement, a heavily negotiated master services agreement, or a contract assembled from several templates.
False negatives and false positives also call for different controls. If the system tends to over-flag, the organization may need triage rules and reviewer calibration. If the system tends to miss issues, the organization needs sampling, mandatory human review for high-risk provisions, and exception reports. If the risk is hallucinated explanation, the output should be tied back to cited contract language and reviewers should avoid accepting free-form reasoning without source verification.
Hallucination Research Is Boundary Evidence, Not a Contract Benchmark
The strongest public hallucination studies do not measure contract analysis directly, so they should not be imported mechanically into contract review. Stanford RegLab’s 2024 study assessed leading legal research tools and found that even premium retrieval-augmented legal AI systems hallucinated 17% to 34% of the time on legal research queries.[5] That is not a clause extraction result.
The warning still matters. The study undermines a lazy assumption that legal branding, retrieval-augmented generation, or access to legal sources eliminates fabrication. If a legal research system can produce unsupported answers while connected to source material, a contract analysis workflow should not treat “RAG-powered” as a substitute for output verification.
Stanford HAI has reported even higher hallucination rates for general-purpose chatbots on legal queries, ranging from 58% to 82%, while noting that purpose-built legal AI reduces but does not eliminate hallucinations.[6] Again, those are legal-query findings, not contract-review accuracy rates. Their relevance is architectural and behavioral: general models are more likely to produce confident legal-sounding answers outside a constrained task environment.
That distinction is important for contract teams. A tool used only to locate an assignment clause presents a different hallucination profile from a tool asked to explain whether an assignment restriction is market, enforceable, and worth negotiating. The more the output resembles advice, the more the organization should require source citations, policy mapping, and human signoff.
Documented AI Legal Failures Show Consequence, Not Frequency for Contract Review
Real-world legal AI failures are no longer anecdotal in the casual sense. Damien Charlotin’s AI Hallucination Cases Database listed 1,696 documented cases across more than 40 jurisdictions as of July 2026, including 663 involving lawyers and 991 involving pro se filings.[7]
That database should not be treated as a contract analysis failure rate. It is not limited to contract review, and its composition includes many filings outside institutional legal departments. It does, however, show that unsupported AI outputs can travel into real legal processes and create sanctions, corrections, embarrassment, or client harm. For contract teams, the lesson is not that every AI output is suspect. It is that consequential legal uses need a review protocol before the first bad output appears.
What to Ask Before Trusting an Accuracy Claim
A useful benchmark should let a legal team map the tested condition onto its own workflow. If it cannot, the headline number may still be interesting, but it is not yet operational.
- What contract type was tested? NDA performance should not be assumed to transfer to employment, procurement, licensing, M&A, or bespoke commercial agreements.
- What task was scored? Clause extraction, absence checks, deal-point analysis, risk scoring, and negotiation guidance should not be collapsed into one accuracy claim.
- What metric was used? F1 score, precision, recall, issue-level accuracy, provision-level accuracy, and human preference ratings answer different questions.
- Who published the benchmark? Independent studies, vendor benchmarks, and unverified industry claims can all be useful, but they deserve different evidentiary weight.
- What counted as failure? A missed high-risk clause, an unnecessary flag, and a hallucinated recommendation should not be treated as equivalent.
- Was the benchmark replicated on unfamiliar documents? A tool can perform well on standardized contracts and degrade when the form, drafting style, or governing logic changes.
These questions matter more than a generic demand for “human review.” Human review is not one thing either. It can mean full rereading, targeted validation of extracted fields, sampling, escalation of high-risk clauses, comparison against a playbook, or signoff by subject-matter counsel. The right layer depends on the failure mode the benchmark suggests.
For example, if a tool is strong at finding standard confidentiality clauses but weak at absence checks, the review protocol should not spend equal time rechecking every positive identification. It should require separate confirmation that missing provisions are truly missing. If a tool struggles with thresholds and multi-part requirements, reviewers should focus on caps, carveouts, exceptions, notice periods, survival language, and cross-references. If the risky output is negotiation guidance, the team should verify not only the cited language but also the business rule the recommendation claims to apply.
A Calibrated Trust Model for AI Contract Analysis
The benchmark evidence supports bounded use of AI contract analysis. It does not support blind reliance on a single accuracy number, and it does not support blanket rejection of the technology. The more defensible position is calibrated trust.
| Use case | Trust level suggested by the evidence | Verification layer |
|---|---|---|
| Standardized, high-volume clause extraction | Higher, if the tool has been tested on comparable documents | Sampling, exception review, and periodic benchmark refresh |
| Absence checks and required-provision review | Moderate | Mandatory verification for provisions that drive risk allocation |
| Deal-point extraction involving thresholds, carveouts, or cross-references | Moderate to low without specialized tooling | Targeted lawyer review of extracted values and linked provisions |
| Risk scoring against a company playbook | Conditional | Policy mapping, audit logs, and escalation rules |
| Negotiation guidance or legal advice-like output | Lowest | Source-grounded explanation and lawyer approval before use |
This model also helps legal teams avoid two common mistakes. The first is treating vendor-reported benchmark performance as if it automatically transfers to the company’s document set. The second is testing a tool only on easy examples, then discovering later that the real risk sits in messy amendments, nonstandard templates, embedded schedules, or provisions that matter precisely because they are unusual.
A serious pilot should therefore include the organization’s own contract mix, known edge cases, and examples where the right answer depends on absence, thresholds, exceptions, or multiple provisions read together. It should measure false negatives separately from false positives. It should distinguish extraction accuracy from recommendation quality. And it should decide in advance which outputs can be accepted automatically, which require sampling, and which always require legal review.
Readers moving from benchmark interpretation to implementation may want more detail on clause extraction benchmark methodology, the professional responsibility framework for AI contract review, the ethics gap between AI contract review and general-purpose AI, or the due diligence questions in an AI contract review buyer’s guide. Accuracy is only one part of deployment; security and data governance deserve their own review as well.
The practical conclusion is narrow but useful: benchmark evidence supports AI contract analysis where the contract type is known, the task is bounded, the architecture fits the work, and the verification layer is designed around the tool’s actual failure modes. A headline accuracy rate can start that conversation. It cannot finish it.
References
- LawGeex Hits 94% Accuracy In NDA Review Vs 85% For Human Lawyers, Artificial Lawyer, February 26, 2018.
- Contract Intelligence Benchmark, Harvey AI, 2025.
- AI Contract Review Software, LegalOn Tech, 2026.
- AI for Contract Review, Helium42.
- Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools, Stanford RegLab, 2024.
- AI on Trial: Legal Models Hallucinate in 1 out of 6 or More Benchmarking Queries, Stanford HAI.
- AI Hallucination Cases Database, Damien Charlotin.
Comments
Join the discussion with an anonymous comment.