Full profile
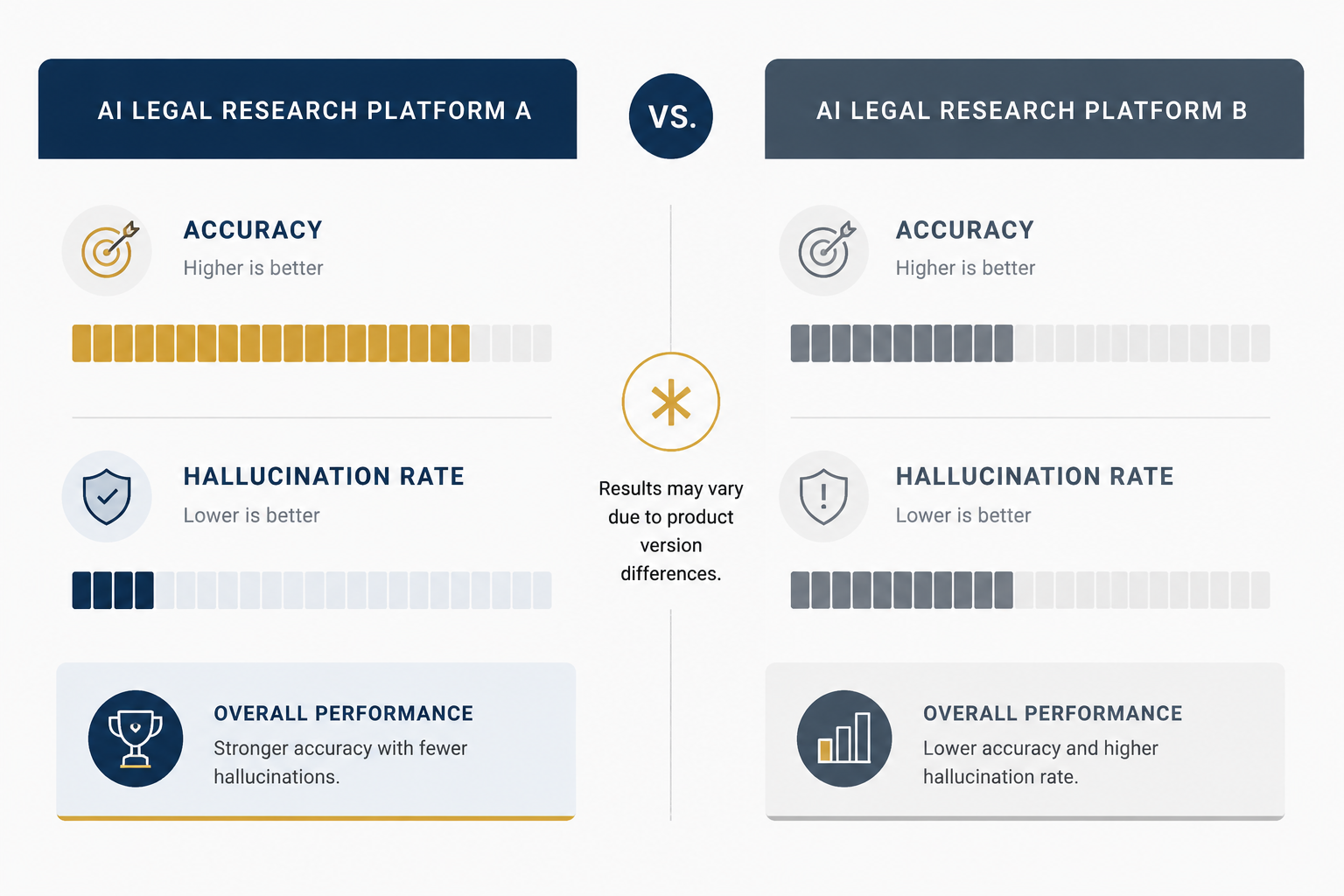
For a CoCounsel vs Lexis+ AI comparison, the fast answer is this: Lexis+ AI, now Lexis+ with Protégé, has the stronger independent evidence today. In the peer-reviewed Stanford/Yale benchmark published in the Journal of Empirical Legal Studies, Lexis+ AI answered 65% of tested legal research queries accurately, while Westlaw AI-Assisted Research answered 42% accurately; Lexis also produced a lower hallucination rate, at about 17% compared with about 33% for Westlaw AI-Assisted Research.[1]
That does not end the procurement analysis. The benchmark tested Westlaw AI-Assisted Research, not the current rebuilt CoCounsel Legal. LexisNexis also replaced the Lexis+ AI branding with Lexis+ with Protégé in February 2026, so older benchmark and pricing discussions often use the prior product name for what is now part of a broader workflow platform.[2] The fairest conclusion is narrower than a vendor slide would prefer: Lexis has the better peer-reviewed head-to-head result; CoCounsel Legal has an unresolved evidence gap after its rebuild; neither platform earns trust without lawyer verification.

What the Stanford/Yale Benchmark Actually Tested
The most useful evidence is Magesh et al., “Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools,” because it is not a marketing survey, a vendor demo, or an ad hoc test. The study was preregistered, peer-reviewed, and built around more than 200 legal queries across several legal research tasks. It tested Lexis+ AI, Westlaw AI-Assisted Research, Ask Practical Law AI, and general-purpose models, then separated correct answers from hallucinated, incomplete, and misgrounded responses.[1]
The distinction matters. A lawyer reviewing an AI answer is not only asking whether the final sentence sounds right. The lawyer needs to know whether the cited authority exists, whether it says what the tool claims, whether it supports the proposition at the level of specificity required, and whether the answer omits a controlling caveat. The benchmark’s “misgrounded” category is especially important because legal-native tools can produce citations that are real but do not support the proposition attached to them.[1]
| Benchmark item | Lexis+ AI | Westlaw AI-Assisted Research |
|---|---|---|
| Accuracy | 65% | 42% |
| Hallucination rate | About 17% | About 33% |
| Product status in 2026 | Renamed and expanded into Lexis+ with Protégé | Predecessor to the rebuilt CoCounsel Legal product |
| Best-supported procurement reading | Stronger independent benchmark evidence | No current independent re-benchmark for the rebuilt product |
The accuracy gap is large enough to matter. A tool that answers roughly two-thirds of benchmark questions accurately is not in the same evidentiary position as one that answers less than half accurately. But neither figure is close to the standard lawyers apply when a proposition will appear in advice, a demand letter, a brief, or a board memo. In practice, a 65% accurate research assistant may save time only if the verification workflow is disciplined enough to catch the remaining failures.
That is why the benchmark should influence platform selection without being converted into a permission slip. Lexis performed better in the tested environment. It did not become a substitute for the research attorney’s judgment.
Why Hallucination Rate Is Not the Whole Risk
The headline hallucination numbers are useful, but the professional risk is broader than a fake case name. The Magesh study identified failures that can look respectable at first pass: real cases attached to unsupported propositions, partial answers that miss adverse authority, and citations that create the appearance of legal grounding while failing the actual support test.[1]
That is the failure mode that creates late-stage cleanup. A nonexistent citation is embarrassing but often easy to catch. A real citation used for the wrong legal proposition is more dangerous because it can survive a skim, especially when the answer is written in the voice of a confident research memo. The reviewing lawyer has to move from citation existence to citation fit.
Stanford HAI’s summary of the study put the practical point plainly: even legal-specific systems hallucinated at meaningful rates, with the leading systems producing hallucinations in at least one out of six benchmark queries.[3] That summary is not a separate benchmark, but it is a useful reminder that legal-native retrieval and citation features reduce some risks without removing the review burden.
The Answer-Length Caveat Helps Explain Part of the Gap
One plausible caveat is answer length. Vaquill AI’s 2026 comparison noted that Westlaw’s benchmark answers averaged about 350 words, with a standard deviation of 120, while Lexis averaged about 219 words, with a standard deviation of 114.[4] Longer answers create more surface area for mistakes. They also create more propositions for a benchmark reviewer to score.
That caveat should temper overconfident interpretations, not erase the result. If a system produces longer answers and those answers contain more unsupported statements, a research director still has to staff the review of those unsupported statements. A product can be penalized by a benchmark for verbosity, but verbosity is also an operational choice that affects the person checking the work.
The more useful procurement question is therefore not simply “Which tool hallucinated less?” It is “Which tool gives reviewers fewer unsupported propositions to chase, and does its answer style make the verification path clear enough for the firm’s workflow?” On the independent evidence available, Lexis had the advantage in the tested products. The answer-length issue is a reason to inspect output format during a pilot, not a reason to treat the benchmark as unknowable.
Vendor Objections and Single-Digit Claims Do Not Carry the Same Weight
Thomson Reuters publicly disputed aspects of the Stanford/Yale methodology. That objection belongs in the file. Benchmarks can be sensitive to query design, product configuration, answer length, scoring rules, and whether the tested workflow resembles ordinary user behavior. A serious buyer should read the methodology rather than quote the leaderboard.
Still, a vendor objection is not equivalent to an independent peer-reviewed replacement study. The Magesh benchmark remains the strongest public head-to-head evidence because it disclosed its design, separated error types, and subjected the work to peer review.[1] If a vendor believes the benchmark understates current performance, the clean answer is not a press objection; it is a new independent benchmark of the current product.
The same caution applies to newer single-digit hallucination estimates. AI Vortex reports substantially lower hallucination figures, including “under 3%” for Lexis+ AI and “5-6%” for Westlaw Precision.[5] Those figures conflict with the Stanford/Yale results, and the methodology behind the newer estimates is not disclosed in a way that makes them comparable to the peer-reviewed benchmark. They may be worth tracking as market signals, but they should not displace the independent study in an adoption memo.
Pricing deserves similar restraint. Third-party comparisons commonly estimate all-in legal AI research pricing in the range of $300 to $500 per seat per month, but neither vendor publishes official AI-tier pricing.[4] That means pricing should be confirmed through the actual proposal, not copied from a comparison article into a budget model as if it were a filed tariff.
The CoCounsel Legal Problem: The Product Changed
The hardest part of a 2026 CoCounsel vs Lexis+ AI comparison is that “CoCounsel” is no longer a clean proxy for the Westlaw product tested in the Stanford/Yale benchmark. The study tested Westlaw AI-Assisted Research and Ask Practical Law AI, not the rebuilt CoCounsel Legal that Thomson Reuters began rolling out through next-generation early access in 2026.[1][6]
LawNext reported in June 2026 that Thomson Reuters opened early access to the next generation of CoCounsel Legal, describing a rebuilt product using Anthropic’s Claude Agent SDK and a general availability target in August 2026.[6] As of July 4, 2026, no independent peer-reviewed re-benchmark of that rebuilt CoCounsel Legal product is available in the materials reviewed.
That product-version gap cuts both ways. It would be unfair to say the Stanford/Yale Westlaw AI-Assisted Research score proves how the rebuilt CoCounsel Legal will perform. It would also be premature to assume the rebuild fixes the measured problems. A new architecture, a different agent framework, and a renamed workflow may improve performance, but they do not create evidence until someone tests the current system under disclosed conditions.
For a renewal committee, the practical treatment is straightforward: Lexis+ with Protégé can point to stronger independent benchmark evidence for its predecessor-branded research product; CoCounsel Legal should be evaluated through a current pilot with documented verification checks, because the public benchmark record has not caught up with the rebuilt product.
How to Read the 65% vs 42% Result in a Buying Decision
A platform decision can reasonably give Lexis the evidentiary edge. The head-to-head benchmark favors Lexis on both accuracy and hallucination rate, and the citation-grounding analysis matches the risk lawyers actually face.[1] If two vendors are otherwise comparable on coverage, workflow fit, security, contract terms, and user adoption, that independent result should matter.
But the score should not be used as a standalone procurement answer. A firm choosing between the products still needs to test representative research questions from its own practice areas, measure reviewer time, record unsupported propositions, and document whether the tool’s citations can be checked efficiently. A legal research platform that is more accurate in a benchmark can still be a poor fit if its output format slows review or encourages users to accept plausible summaries too quickly.
For readers who need a broader vendor-by-vendor view, the comparison in Westlaw CoCounsel vs Lexis+ AI covers more of the surrounding product and compliance context. For readers aggregating multiple accuracy studies, AI legal research accuracy benchmarks is the better place to compare evidence outside this Stanford/Yale study.
Verification Is Not a Feature; It Is the Lawyer’s Job
The professional responsibility analysis is not an afterthought to the benchmark. It is the point at which the numbers become operational. ABA Formal Opinion 512 applies existing duties of competence, confidentiality, communication, candor, supervision, and fees to generative AI use. For research tools, Model Rule 1.1 and Model Rule 5.3 are the center of gravity: lawyers must understand the technology well enough to use it competently and must supervise nonlawyer assistance, including assistance delivered through a vendor system.
That means the better benchmark result does not change the review obligation. If Lexis+ with Protégé returns a cited proposition, the reviewer still checks the authority. If CoCounsel Legal returns a polished answer after its rebuild, the reviewer still checks the authority. The duty is not satisfied by choosing a reputable vendor, buying a legal-native tool, or pointing to a lower hallucination percentage.
A workable verification protocol should treat every AI answer as a draft research lead. At minimum, the reviewer should confirm that cited authorities exist, read the relevant passages, test whether the cited authority supports the proposition, Shepardize or KeyCite as appropriate, and check whether controlling contrary authority or statutory updates change the answer. The more consequential the use, the more the process should look like conventional legal research rather than cite-cleaning.
Firms that need a mapped ethics framework can use the ABA Formal Opinion 512 compliance guide. Teams building the day-to-day workflow may be better served by a concrete Prompt → Verify → Audit protocol or a six-phase hallucination audit checklist. Those materials matter because the adoption decision is only half the control. The other half is whether anyone can later show how outputs were checked.
Bottom Line for 2026
Lexis+ with Protégé has the stronger independent evidence in this comparison because Lexis+ AI outperformed Westlaw AI-Assisted Research in the only peer-reviewed public head-to-head benchmark. The 65% versus 42% accuracy gap and the lower hallucination rate are meaningful, especially because the study examined citation grounding rather than just obvious fabrications.[1]
CoCounsel Legal’s current position is less settled. The Stanford/Yale result should not be treated as a direct score for the rebuilt 2026 product, but there is also no independent re-benchmark in the record that proves the rebuild has closed the gap. Until that evidence exists, a buyer should separate the predecessor-product benchmark from current-product claims and require its own documented pilot.
The adoption-level judgment is therefore limited but useful: Lexis has the better public benchmark support today; CoCounsel Legal has a current-product evidence gap; and no available platform result relieves lawyers of manual verification of every AI-generated citation and legal proposition.
References
- Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools — Journal of Empirical Legal Studies, 2025
- LexisNexis Launches Lexis+ with Protégé, Replacing Lexis+ AI with an End-to-End Workflow Platform — LawNext, February 2026
- AI on Trial: Legal Models Hallucinate in 1 out of 6 (or More) Benchmarking Queries — Stanford HAI
- Lexis AI vs Westlaw AI — Vaquill AI, 2026
- Which AI Is Most Accurate for Legal Research? — AI Vortex
- Thomson Reuters Opens Early Access to the Next Generation of CoCounsel Legal, Saying Beta Users ‘F’ing Loved’ the Product — LawNext, June 2026
Comments
Join the discussion with an anonymous comment.