Why Playbooks Are the Legal Intelligence Layer for AI Contract Review
The AI model powering your contract review tool is only as good as the instructions it receives. Without a structured playbook — a set of encoded business rules, preferred positions, and escalation criteria — even the most sophisticated large language model will produce inconsistent, off-market redlines that require extensive human rework. The playbook is the legal intelligence layer that transforms a general-purpose language model into a tool that reflects your organization's specific risk appetite and negotiation strategy.
Yet most in-house teams operate without this critical layer. According to LegalOn's 2025 State of Contracting survey of 286 legal professionals, 54% of in-house legal teams have no playbook at all, and 95% report gaps in the coverage of the playbooks they do have. The consequences are measurable: the average legal team spends 3.2 hours reviewing a single contract. For a team handling 500 contracts annually, that adds up to 1,600 hours — roughly 200 working days — consumed by manual review. Those hours are not spent on strategic work like deal structuring, risk advisory, or compliance planning.
The thesis of this guide is straightforward: a well-structured playbook is the single highest-leverage investment you can make in AI contract review accuracy. The AI model handles the language processing; the playbook supplies the legal judgment. Building one from scratch may seem daunting, but the process is systematic, repeatable, and — as this article will demonstrate — achievable in stages that deliver value from the first clause you encode.
This article assumes you have already selected an AI contract review tool. If you are still evaluating platforms, refer to our category-based comparison of AI contract review software to understand which platforms offer the strongest playbook automation features. Once you have a tool, the playbook is what makes it yours.
Anatomy of an AI-Ready Playbook: Preferred Positions, Fallback Language, and Escalation Thresholds
A playbook entry that an AI tool can execute reliably contains three distinct components. Each serves a specific function in the redlining and review workflow.
- Preferred or standard position: The exact language your organization wants to see in the final contract. This is the starting point for AI-generated redlines. If the counterparty's draft deviates from this language, the AI flags the difference and proposes the preferred version.
- Fallback language: Acceptable alternatives when the counterparty rejects the preferred position. Fallback language defines the boundaries of what your team will accept without escalating to a senior attorney. Well-defined fallbacks reduce negotiation friction and speed up the review cycle.
- Escalation thresholds: Conditions that trigger mandatory human review. These include counterparty proposals that fall outside both the preferred and fallback positions, requests for unusual terms, or deviations in high-risk clauses where the organization requires attorney judgment regardless of the proposed language.
Consider a confidentiality clause as a concrete example. The preferred position might specify a 5-year term with no exceptions for publicly available information. The fallback language might accept a 3-year term with standard exceptions. The escalation threshold might trigger human review if the counterparty proposes perpetual confidentiality or excludes all information disclosed orally. With these three components encoded, the AI can redline the clause autonomously for most counterparty proposals and only escalate when the proposal falls outside the defined boundaries.
| Component | Definition | Example (Confidentiality Clause) |
|---|---|---|
| Preferred Position | The language your team wants to see | 5-year confidentiality term, no exceptions for publicly available information |
| Fallback Language | Acceptable alternatives | 3-year term with standard exceptions for publicly available, independently developed, and rightfully received information |
| Escalation Threshold | Conditions requiring human review | Perpetual term; exclusion of oral information; any liquidated damages provision for breach |
Not every clause needs all three components defined from day one. Start with the preferred position for your highest-volume clauses, then layer in fallback language and escalation thresholds as you observe patterns in counterparty pushback. The goal is to build a system that handles the routine 80% of reviews autonomously while surfacing the genuinely novel or high-risk issues for attorney attention.
Start With the 'Great 8': High-Impact Clauses for Your First Playbook
Building a comprehensive playbook covering every conceivable clause type is a recipe for paralysis. The more practical approach is to start with the clauses that appear most frequently in your contracts and carry the highest risk exposure. LegalOn's framework identifies eight such clauses — the 'Great 8' — that should form the foundation of any AI-ready playbook.
- Intellectual Property
- Limitation of Liability
- Indemnification
- Confidential Information
- Data Protection & Security
- Warranties
- Payment Terms
- Effects of Termination
These eight clauses share three characteristics that make them ideal starting points. First, they appear in the majority of commercial contracts — NDAs, MSAs, DPAs, and SaaS agreements all contain variations of these terms. Second, they carry disproportionate risk: a poorly negotiated limitation of liability or indemnification clause can expose the organization to significant financial exposure. Third, they are the clauses most frequently negotiated, meaning your team already has institutional knowledge about what positions are acceptable and which counterparty proposals require escalation.
To prioritize within the Great 8, analyze your team's contract volume by clause type. If you handle more data processing agreements than software licenses, start with Data Protection & Security before Intellectual Property. If your organization operates in a regulated industry where warranty disclaimers are heavily negotiated, prioritize Warranties. The framework is a starting point, not a rigid sequence.
Encoding Rules With Precision: From Vague Guidance to Actionable AI Instructions
The most common mistake teams make when building their first AI playbook is encoding rules the way they would write guidance for a human associate. Vague instructions like 'Review for lengthy breach notification periods' or 'Ensure confidentiality obligations are reasonable' are nearly useless for an AI system. The model cannot determine what counts as 'lengthy' or 'reasonable' without explicit parameters.
Effective AI playbook rules are specific, measurable, and binary wherever possible. LegalOn provides a clear example of this distinction. Instead of writing 'Review for lengthy breach notification,' encode: 'The contract must include a 24-hour breach notification requirement.' The AI can check for the presence of a 24-hour notification period, flag its absence, and propose the preferred language — all without ambiguity.
| Vague Rule (Ineffective) | Specific Rule (Effective) | Why It Matters |
|---|---|---|
| Review for lengthy breach notification | Must include a 24-hour breach notification requirement | AI can verify a specific time period; cannot evaluate 'lengthy' |
| Ensure indemnification is mutual | Indemnification must be mutual for IP infringement claims, capped at total contract value | Specifies scope, trigger event, and cap — all machine-checkable |
| Limit liability appropriately | Liability cap must not exceed total fees paid over the prior 12 months, with exceptions for IP infringement, confidentiality breach, and death/personal injury | Defines the cap formula and carveouts explicitly |
| Data protection should be reasonable | Must include SOC 2 Type II certification requirement, 30-day breach notification, and DPA incorporating Standard Contractual Clauses | Lists specific, verifiable requirements |
When encoding rules, also consider the format of the expected output. Some AI tools can insert redlined language directly into a document; others flag deviations and present proposed language in a sidebar. Design your rules to match the tool's output capabilities. If your tool supports automated redlining, include the exact replacement language in the rule. If it only flags deviations, focus on clear detection criteria and leave the drafting to the reviewer.
Using AI to Generate First-Draft Playbooks From Templates and Historical Data
Building a playbook from scratch does not mean starting with a blank page. Several vendors, including Epiq in a pilot program, are using generative AI to produce first-draft playbooks by analyzing standard templates and historical executed contracts. The AI breaks down provisions, identifies common pushbacks, and suggests fallback language — all without requiring a senior attorney to manually draft each rule.
The workflow for AI-assisted playbook generation follows four steps:
- Assemble a representative set of 10–20 well-negotiated contracts that reflect your organization's standard positions and common deviations. Include both fully executed agreements and templates where available.
- Upload the contracts to your AI contract review platform and instruct it to extract clause patterns, identify preferred positions, and note where counterparties commonly pushed back.
- Review the AI-generated draft playbook clause by clause. The AI will suggest preferred language, identify fallback positions it observed in the historical data, and flag clauses where the data shows significant variation — indicating areas that may need escalation thresholds.
- Have a senior attorney approve the final playbook before deployment. The AI draft accelerates the process, but human validation is essential for accuracy and business alignment.
This approach reduces the initial setup burden significantly. Instead of spending weeks manually drafting playbook entries for each clause, your team can review and refine an AI-generated draft in days. The caveat is that the quality of the output depends heavily on the quality of the input contracts. If your historical contracts contain inconsistent positions or outdated language, the AI will replicate those inconsistencies. Curate your input set carefully.
Maintaining Playbooks With GenAI: Real-Time Regulatory Alerts and Historical Outcome Analysis
A playbook is not a set-it-and-forget-it asset. It decays as regulations change, market norms shift, and your organization's risk appetite evolves. A data protection clause that was adequate under the previous regulatory regime may be non-compliant after a new law takes effect. A limitation of liability cap that was standard in your industry two years ago may now be off-market.
Generative AI can address the maintenance challenge in two ways. First, it can monitor legal and regulatory databases for relevant changes and flag playbook entries that need revision. For example, if a state enacts a new data breach notification law with a shorter timeline, the AI can identify every playbook entry that references breach notification periods and alert the team to update them. Epiq's approach integrates Gen AI with legal and regulatory databases to provide these real-time alerts.
Second, AI can analyze historical negotiation outcomes to show which fallback positions are accepted most frequently. This data helps teams identify where their standard positions are off-market — meaning counterparties consistently reject them — and where they can reduce negotiation friction by adjusting their preferred language. If your team's preferred indemnification cap is accepted only 20% of the time, but a slightly higher cap is accepted 80% of the time, the data supports a conversation about whether the standard position is worth the negotiation cost.
- Track acceptance rates for preferred vs. fallback positions across all negotiated contracts.
- Identify clauses where counterparty pushback consistently exceeds the escalation threshold — these may indicate that the preferred position is unrealistic for your market segment.
- Review playbook entries quarterly against current regulatory requirements and industry benchmarks.
- Update escalation thresholds based on observed patterns — if a clause type never actually requires senior attorney intervention, consider expanding the fallback options to reduce unnecessary escalations.
Layered Playbooks: Matching Guardrails to Negotiator Experience Level
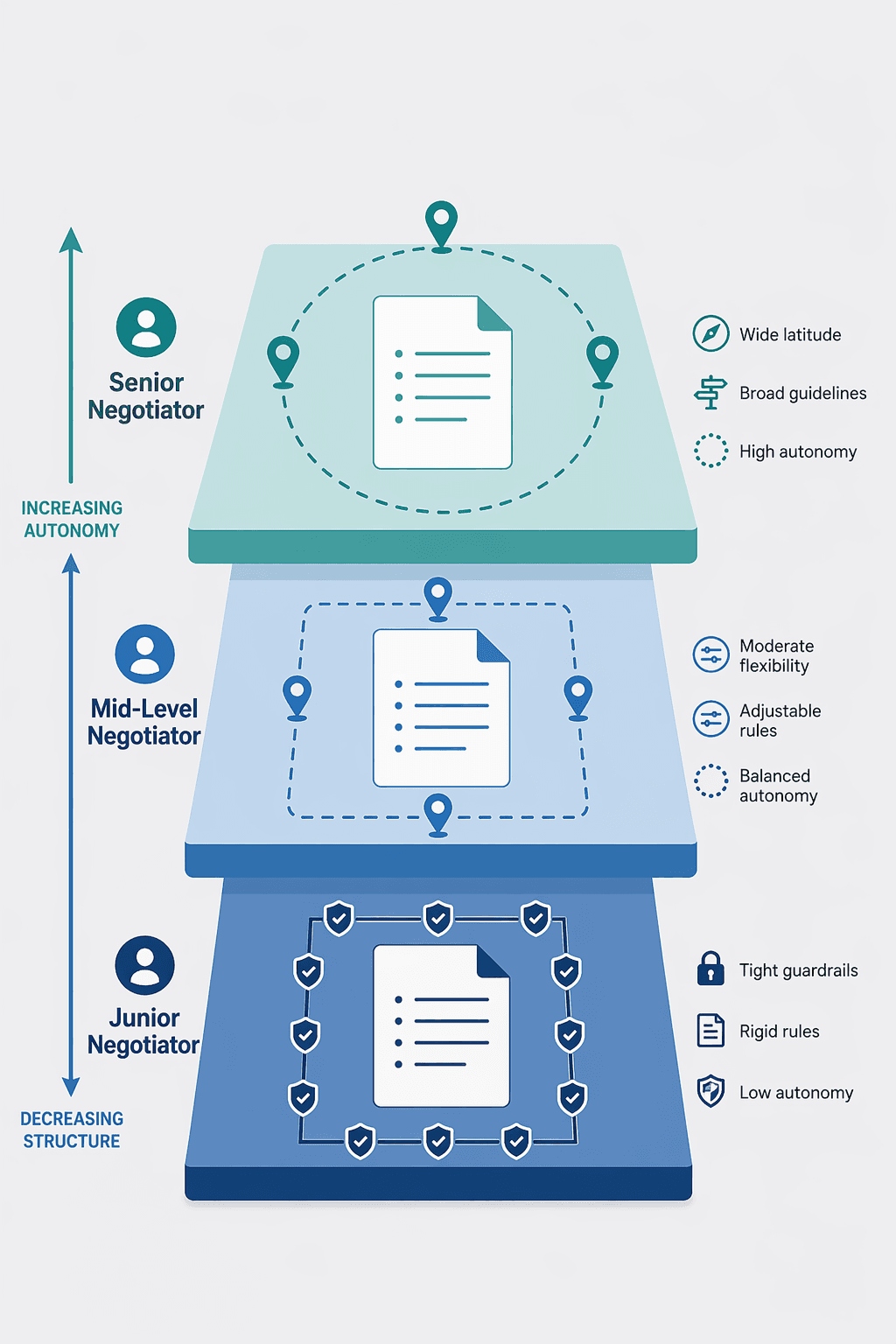
Not everyone on your legal team needs the same level of playbook guardrails. A junior contract manager reviewing a low-risk vendor agreement can operate effectively with tight constraints and limited deviation authority. A senior counsel negotiating a strategic partnership needs broader boundaries and the ability to exercise judgment on novel issues. Layered playbooks — different rule sets for different experience levels — address this organizational reality.
Epiq's framework for layered playbooks assigns three tiers of guardrails based on the negotiator's role and experience:
| Tier | Typical Role | Guardrail Level | Fallback Options | Escalation Triggers |
|---|---|---|---|---|
| Junior | Contract manager, junior associate, procurement specialist | Tight — limited to preferred position with 1–2 predefined fallbacks | 2–3 approved alternatives per clause | Any deviation outside fallback options; any clause not in the playbook |
| Mid-Level | Mid-level associate, senior contract manager | Moderate — broader fallback range, some deviation authority | 3–5 approved alternatives; can accept minor deviations within defined parameters | Deviations exceeding defined parameters; novel legal issues; high-value contracts above a threshold |
| Senior | Senior counsel, legal director, general counsel | Broad — minimal predefined constraints, maximum autonomy | No predefined fallbacks; can negotiate within business-approved risk boundaries | Only structural changes (e.g., changing governing law, adding unusual termination rights) |
Implementing layered playbooks requires your AI contract review tool to support role-based permissions and rule sets. Not all platforms offer this capability. When evaluating tools, ask whether the platform can apply different playbook versions based on the reviewer's identity or role. If your tool does not support layered playbooks natively, you can approximate the approach by maintaining separate playbook documents for different teams and manually assigning them based on the reviewer's experience level.
The key benefit of layered playbooks is that they prevent two failure modes simultaneously. Junior reviewers are not left without guidance — they have clear boundaries that prevent them from accepting unfavorable terms. Senior reviewers are not burdened with unnecessary escalations — they can focus their attention on the genuinely complex issues that require their expertise.
Measuring Playbook Effectiveness: KPIs for Coverage, Consistency, and Speed
Once your playbook is deployed, you need metrics to evaluate its effectiveness and identify gaps. Three key performance indicators provide a comprehensive view of playbook quality and AI performance.
| KPI | Definition | Target Range | Why It Matters |
|---|---|---|---|
| Coverage Rate | Percentage of clauses in incoming contracts that have an encoded playbook rule | 80–95% for high-volume contract types | Low coverage means the AI cannot review significant portions of the contract autonomously, defeating the purpose of the playbook |
| Deviation Capture Rate | Percentage of non-standard clauses correctly flagged by the AI | 85–95% (Sirion benchmarks) | Missed deviations create risk exposure; false positives waste reviewer time on non-issues |
| Time to First Draft | Hours from contract receipt to first AI-generated redline | 1–2 hours (down from 4–8 hours manually, per Sirion) | Directly measures the speed benefit of playbook-driven review; the primary ROI driver |
Sirion's published benchmarks provide aspirational targets for these metrics. According to Sirion, well-encoded playbooks improve consistency across reviewers from 60–70% to 95–98% and risk identification accuracy from 65–80% to 85–95%. The same data suggests that AI playbook-driven redlining reduces contract review cycles by 45–90% compared to manual processes, with average review time per contract dropping from 4–8 hours to 1–2 hours.
These metrics feed back into the maintenance loop. If coverage rate is low for a particular contract type, prioritize building rules for the missing clauses. If deviation capture rate is below target, review the specificity of your encoded rules — vague language is the most common cause of missed deviations. If time to first draft is not improving, examine whether the AI is spending excessive time on clauses that should have been escalated immediately.
Tracking these KPIs over time also builds the business case for continued investment in playbook development. A dashboard showing month-over-month improvement in coverage rate and time savings provides concrete evidence of ROI that leadership can understand. For a broader framework on building the business case for AI contract review adoption, see our ROI analysis for AI contract review, which covers the full implementation roadmap from playbook construction to organization-wide deployment.
Comments
Join the discussion with an anonymous comment.