Full profile
The lesson many lawyers took from Mata v. Avianca was simple enough: do not file cases you have not checked. The more useful technical lesson is narrower. A bare general-purpose language model can write legal-looking prose without ever retrieving the case it claims to cite. That is how fake opinions, fake quotations, and fake reporter citations can arrive in a memo with the same confident tone as a Westlaw printout. For the sanctions history, the better place to start is the risk-digest treatment of AI hallucinations in litigation. Here, Mata is the reason the machinery matters.
RAG, short for retrieval-augmented generation, is the attempt to put that machinery between the user's question and the answer. In plain terms, the system should fetch relevant materials, read them into the model’s working context, and then answer from those materials rather than from the model’s general training memory. That architecture is widely described as a way to reduce hallucinations in legal work, but the reduction is not the same thing as elimination. In a Stanford-led evaluation of leading AI legal research tools, specialized tools still produced incorrect or misleading responses in material rates, while bare GPT-4 performed worse; the published study reports roughly 43% hallucination for bare GPT-4 and 17% to 33% for the tested specialized legal tools, with the important caveat that the tool versions were tested in May 2024 and later releases may differ.[1]
That is the right level of expectation for RAG for legal research explained honestly. It is a grounding method, not a malpractice shield. It can make the source path visible. It can force the answer to confront retrieved text. It can give a reviewing lawyer something to inspect. But if the pipeline retrieves the wrong passage, slices the opinion badly, treats a dissent as the holding, or misses later negative treatment, the final answer can still look orderly while being unsafe.
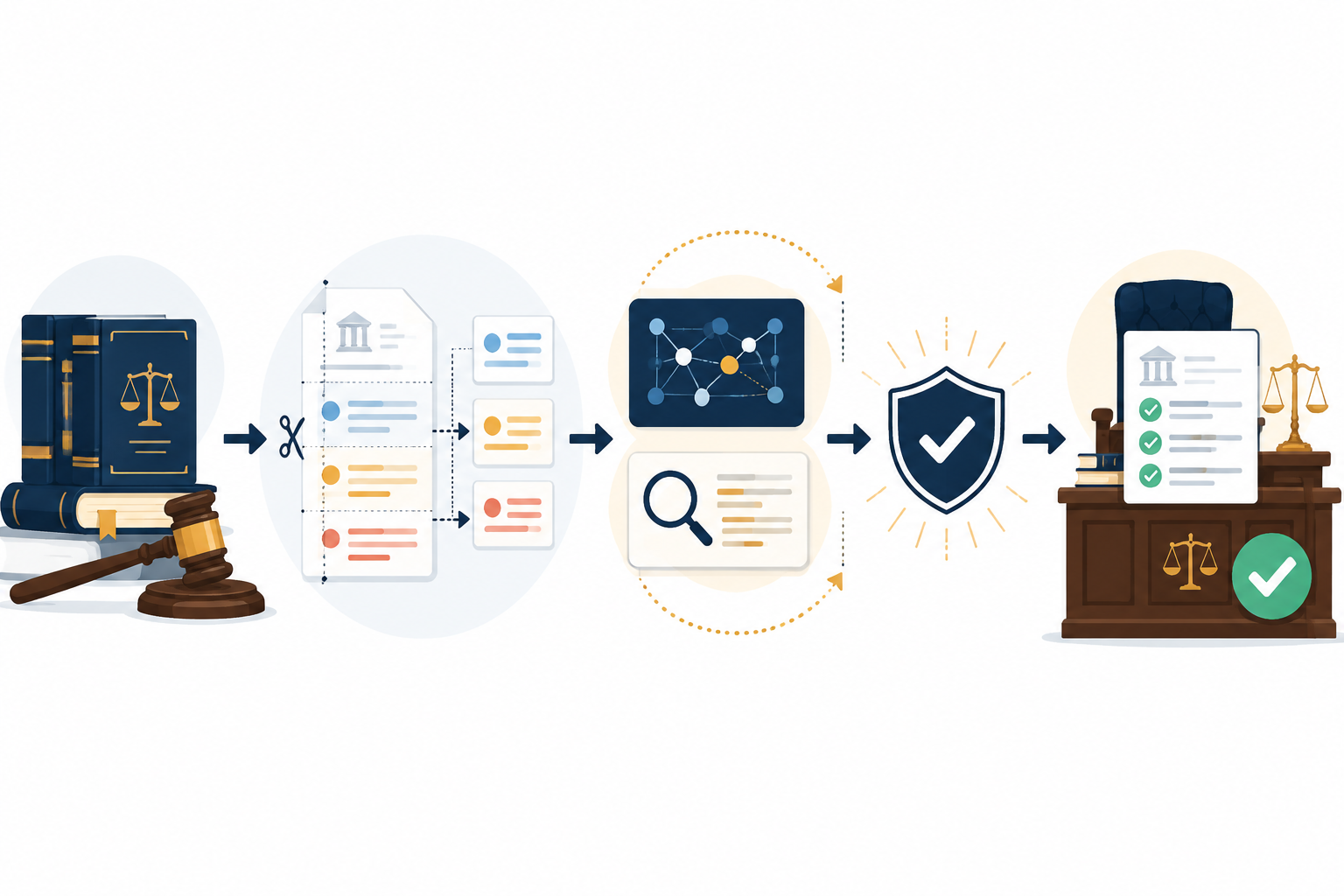
The Short Version: Fetch, Read, Answer
Most RAG explainers start with a clean three-part model. A user asks a question. The system searches an external knowledge base. The model drafts an answer using the returned materials. Legal RAG uses that same basic pattern, and general overviews from legal technology writers describe the promise in similar terms: retrieval gives the model access to legal sources that are more current, more specific, and more auditable than the model’s general training data alone.[2][3]
For a lawyer, the useful question is not whether that sentence is true in the abstract. It is where, exactly, the system can lose legal meaning while still appearing to work. Legal research is full of materials that are semantically close but doctrinally different: majority and dissent, holding and dicta, Fourth Amendment search and Fourth Amendment seizure, Chevron deference before and after Loper Bright. A search system that finds something related has not necessarily found something citable.
| Pipeline stage | What it does | Legal failure to watch |
|---|---|---|
| Ingestion | Loads cases, statutes, regulations, briefs, or firm documents into the system | Missing source metadata, bad OCR, stale collections, or incomplete jurisdictions |
| Citation normalization | Recognizes that parallel citations may point to the same authority | One case splinters into separate records because the system treats U.S., S. Ct., and L. Ed. citations as different items |
| Chunking | Splits long legal documents into smaller passages for retrieval | A holding is detached from posture, or a majority passage is merged with a dissent |
| Embedding and indexing | Turns passages into searchable representations and stores them | Topical similarity substitutes for legal relevance |
| Hybrid retrieval | Combines semantic search with keyword or lexical search | Exact statutory words, party names, or citation strings are missed if the system relies only on embeddings |
| Reranking | Sorts candidate passages by likely usefulness for the question | A broadly relevant passage beats the narrower controlling passage |
| Generation and grounding | Drafts the answer from retrieved passages | The model overstates what the passage says or cites a source for a claim the source does not support |
| Verification and treatment checking | Checks citations, source support, and later authority | The answer cites real but overruled, distinguished, or negatively treated law |
Run One Query Through the Pipeline
Use a concrete research question: “After Carpenter, when does law enforcement access to cell-site location information count as a Fourth Amendment search?” The example is illustrative; actual behavior will vary by vendor implementation, source collection, model, index design, and update schedule. But Carpenter is useful because it sits in a crowded doctrinal neighborhood. Katz, Terry, Riley, Jones, and Carpenter all live near “Fourth Amendment search” in ordinary language. They do not stand for the same rule.
A credible legal RAG system should not merely pull every passage that sounds like privacy, phones, and police investigation. It has to preserve enough structure to tell whether a passage is the Court’s rule, a concurrence’s limiting rationale, a dissent’s warning, or a later court’s application. That work begins before the user ever types the query.
Ingestion Is Where the Source Becomes Machine-Readable
Ingestion is the intake process. The system loads the opinion, extracts text, captures metadata, and stores information such as court, date, jurisdiction, docket number, reporter citations, judges, procedural posture, and document type. For statutes and regulations, the comparable metadata may include jurisdiction, effective date, section hierarchy, amendment history, and source publication.
This stage is less glamorous than embeddings, but it is where many later mistakes are made possible. If the system ingests a slip opinion without later editorial metadata, misses a corrected version, or treats a syllabus as if it were the Court’s opinion, the retrieval stage inherits that confusion. A downstream model can sound careful while relying on a badly labeled source.
Citation Normalization Keeps One Authority From Becoming Three
Legal citations are not just strings. A single Supreme Court decision may appear in U.S. Reports, Supreme Court Reporter, and Lawyers’ Edition formats. Lawyers are used to that. A retrieval system has to be taught it. If a database stores those variants as unrelated identifiers, a query using one citation form may miss passages attached to another form, and citation verification may falsely report that a cited case cannot be found.
Normalization is the mapping layer that says, in effect, these citation strings point to the same legal authority. It also matters when the model drafts an answer. A generated citation should resolve back to the correct case record, not merely resemble a real citation. That distinction is one of the reasons a legal-native system and a general chatbot with browsing can behave very differently; for more on that divide, see the discussion of general-purpose versus legal-native AI risks.
Chunking Is Not a Clerical Detail
RAG systems usually cannot send an entire legal corpus, or even a long opinion set, into the model every time a user asks a question. They split documents into chunks. In ordinary business documents, a chunk might be a few paragraphs with overlap on either side. In legal research, that simple method can be dangerous.
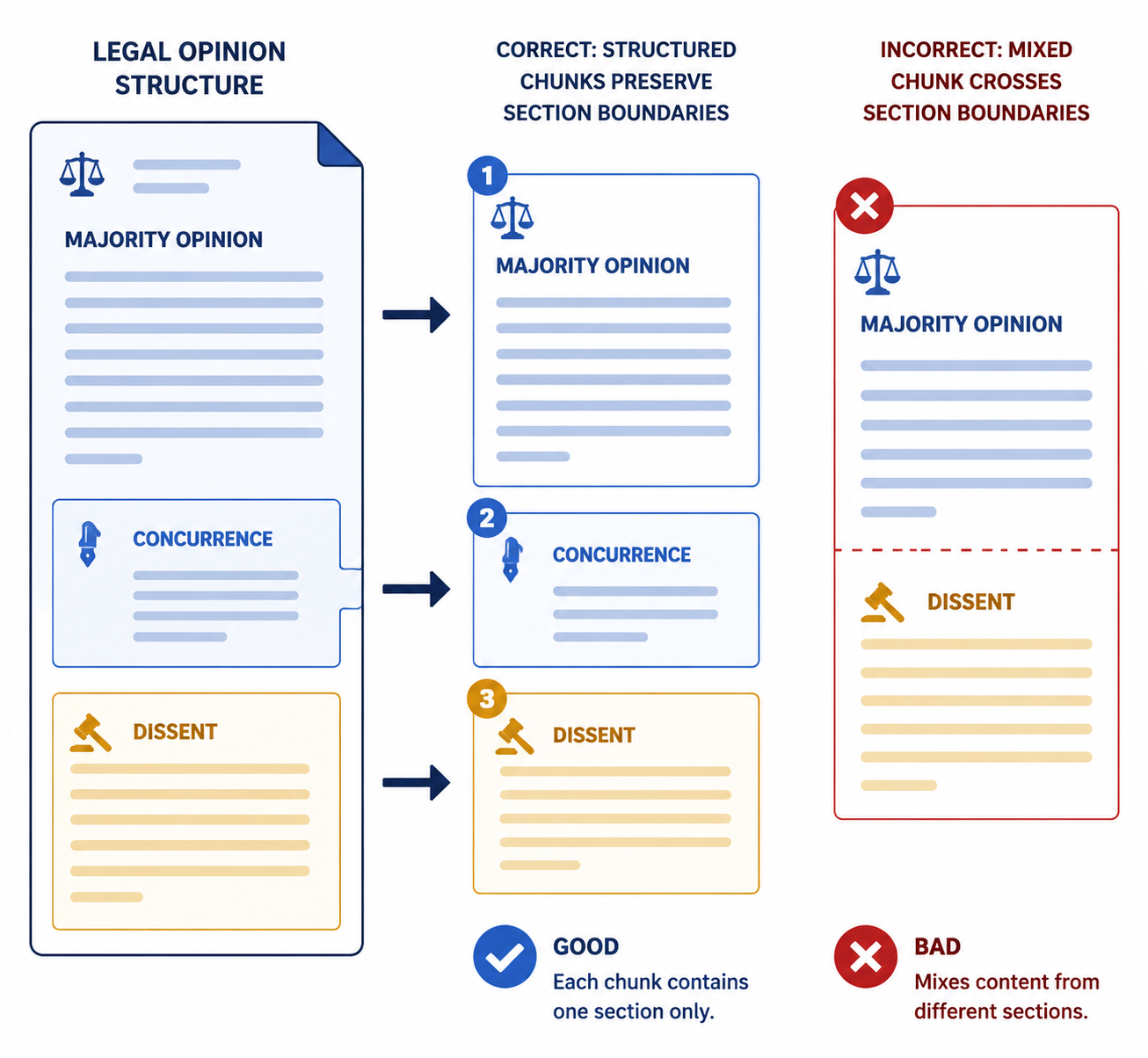
A Supreme Court opinion is not a flat essay. It may contain a syllabus, majority opinion, concurrence, partial concurrence, dissent, footnotes, quoted material, and discussion of procedural history. A district court order may summarize a party’s argument before rejecting it. A brief may quote an opponent’s position in order to attack it. If a chunking strategy ignores those boundaries, it can create passages that no lawyer would treat as a coherent unit of authority.
In the Carpenter query, a poor chunk might place a majority passage about the privacy implications of cell-site location information next to a dissenting passage about administrability. A model asked to summarize the rule may then smooth the two together. Nothing in that failure requires a fake case. The retrieved text can be real and the answer can still misstate the law.
Structure-aware chunking tries to avoid that by preserving labels and boundaries: majority, concurrence, dissent, headnote if included, footnote, quoted authority, procedural history, and holding-bearing discussion. Technical discussions of legal RAG increasingly emphasize contextual chunking for this reason, although the exact methods and quality vary by implementation.[4]
- A useful chunk should know where it came from: case, court, date, section, page or paragraph, and opinion component.
- A useful chunk should not cross from majority to dissent merely because the text window ran out.
- A useful chunk should preserve enough surrounding context to show whether the court is adopting, distinguishing, quoting, or rejecting a proposition.
- A useful chunk should be traceable back to the full document so the reviewing lawyer can inspect the source in context.
Embeddings Find Similarity; Lawyers Need Relevance
After chunking, many RAG systems create embeddings. An embedding is a numerical representation of text that lets the system compare passages by semantic similarity. A passage about cell phone location tracking should sit closer to another passage about digital privacy than to a passage about maritime liens. That is useful. It is also not legal analysis.
The Carpenter query shows the problem. Vector search may correctly retrieve materials about Fourth Amendment searches. But Katz, Terry, Riley, Jones, and Carpenter can all be nearby in embedding space because they discuss searches, privacy, police conduct, and constitutional reasonableness. The lawyer’s question is more particular: what rule applies to historical cell-site location information after Carpenter? Similarity gets the system into the right library aisle. It does not tell the system which volume controls the point.
This is why a system that sells itself only as “semantic search over legal documents” deserves follow-up questions. Semantic search is valuable, but legal research often turns on exact terms, dates, citations, procedural posture, and jurisdictional constraints. A passage that is broadly similar may be less useful than a less poetic passage containing the exact statutory phrase or controlling citation.
Why Hybrid Retrieval Matters
Hybrid retrieval combines vector search with lexical search, often described through methods such as BM25 keyword matching. Vendor and engineering explanations of legal RAG commonly describe this as a practical way to capture both conceptual similarity and exact-match signals.[3][5] In legal work, that combination is not a luxury. It mirrors how lawyers already search.
A lawyer may search conceptually for “warrantless access to phone location data,” then tighten the search with “cell-site location information,” “CSLI,” “reasonable expectation of privacy,” or a known citation. Vector retrieval helps with the first move. BM25-style matching helps with the second. The point is not that one method is smarter. The point is that they fail differently.
| Retrieval method | What it is good at | What it can miss |
|---|---|---|
| Vector search | Finding passages that are conceptually similar even when they use different words | Exact citation strings, statutory wording, defined terms, and doctrinal distinctions hidden inside a broad topic |
| BM25 or keyword search | Finding exact words, names, citations, and phrases | Relevant passages that use synonyms, paraphrase the concept, or frame the issue differently |
| Hybrid retrieval | Balancing semantic similarity with exact-match signals | Still depends on good source metadata, chunking, filters, and ranking |
In the Carpenter example, hybrid retrieval should give weight both to semantically related Fourth Amendment passages and to exact signals such as “cell-site location information” or “CSLI.” It should also allow filters that matter legally: Supreme Court authority, date, jurisdiction, later citing cases, and document type. Without those controls, the system may provide an answer that is topically fluent but jurisdictionally careless.
Reranking Narrows the Stack Before the Model Writes
Initial retrieval may return dozens or hundreds of candidate chunks. Reranking is the sorting step that asks which of those passages best answer the specific user query. In a legal research tool, the reranker should prefer a passage that directly addresses compelled access to historical CSLI over a general passage about expectations of privacy, even if both are semantically close.
This is another place where legal meaning can be flattened. A passage from Carpenter that states the rule should outrank a law review-style overview if the user asked for controlling authority. A later circuit decision applying Carpenter to a different technology may be highly relevant if the user asked for lower-court applications. A dissent may be useful if the user asked for arguments, but not if the user asked for the holding. Good reranking is not merely “most similar first.” It is similarity disciplined by the task.
Generation Is Where the System Must Show Its Work
Only after retrieval and reranking does the language model draft the answer. The model receives the question and selected source passages, then produces prose. This is the stage users see, so it receives too much of the credit and too much of the blame. A polished answer may reflect excellent retrieval. It may also reflect an eloquent model smoothing over weak evidence.
For the Carpenter query, a safe answer should make bounded claims: that Carpenter concerned government acquisition of historical cell-site location records, that the Court treated that acquisition as a Fourth Amendment search, and that the rule should not be casually generalized to every form of location data or every investigative technique without checking later applications. Each proposition should point to a source passage. If the answer says “courts have extended Carpenter to X,” the system should identify which courts, in which cases, and from which passages.
Grounding is the discipline that keeps the generated answer tied to the retrieved record. The question for a reviewer is not “does the answer have citations?” It is “does each cited sentence actually support the proposition it is attached to?” Those are different questions. A citation can be real, accurately formatted, and still not support the sentence preceding it.
Claim-by-Claim Verification Is the Filing-Oriented Test
A production-grade legal research system needs a verification layer that checks the generated answer against the retrieved sources. At minimum, that means mapping each legal proposition to a passage, confirming that cited cases exist, checking that citations resolve to the intended authority, and flagging unsupported or weakly supported claims. This is where the system begins to resemble an auditable research assistant rather than a fast drafting engine.
- The case exists and the citation resolves to the correct authority.
- The cited passage supports the exact proposition, not just the general topic.
- The answer distinguishes holding, dicta, procedural background, quotation, concurrence, and dissent where those distinctions matter.
- The system exposes enough source context for a human reviewer to inspect the passage without trusting the generated paraphrase.
- The tool flags uncertainty instead of forcing a confident answer from thin retrieval.
This is also why reported hallucination rates should be read as evaluation data, not as permanent labels. The Stanford study is valuable because it tested legal research systems rather than assuming that citations solve the problem. It also tested particular versions at a particular time. A buyer or supervising lawyer should ask for current evaluation results, task definitions, and examples of failures, not just a dashboard number.[1]
RAG Does Not Shepardize
The most important omission in ordinary RAG explainers is treatment checking. RAG can retrieve a case. RAG can help summarize the case. RAG can cite a passage from the case. None of that means the case is still good law for the proposition offered.
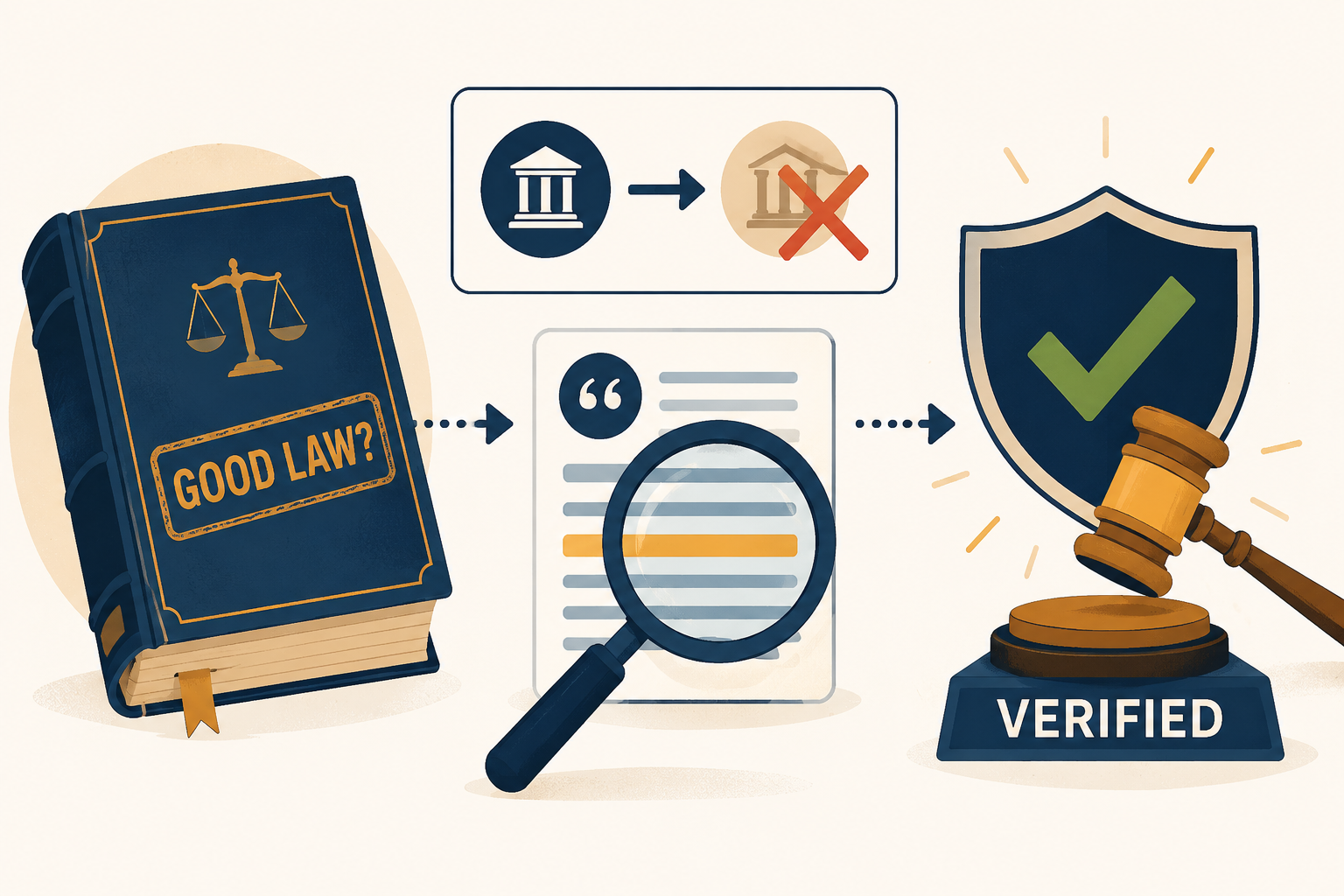
Take the familiar administrative-law example. A retrieval system can surface Chevron because Chevron is highly relevant to questions about agency deference. But after Loper Bright, the validity landscape changed. A RAG pipeline that only searches and summarizes text does not inherently know that later authority has overruled or displaced an older rule. It needs a connected authority-treatment layer: a graph of citing relationships, negative treatment, overruling, abrogation, distinguishing, statutory supersession, and jurisdiction-specific effect. Legal research commentators have emphasized this distinction when discussing hallucinations and knowledge-cutoff problems in AI legal research systems.[6]
That layer is not the same as retrieval. It is closer to the validity infrastructure lawyers expect from citators. The system must know not only that a passage exists, but what later courts and legislatures have done to it. It must also communicate the result in a way a lawyer can inspect: what treated what, when, how, and for which proposition.
This is the difference between an answer that is grounded and an answer that is fileable. Grounding asks whether the cited source says what the answer claims. Treatment checking asks whether that source can still be used that way. Both questions have to be answered before anyone should put the proposition into a brief.
What to Ask When Evaluating a Legal RAG Tool
The practical evaluation should follow the pipeline. A vendor’s explanation may fairly begin with embeddings and citations, but it should not end there. Commercial sources can be useful for understanding implementation patterns, yet claims of product superiority should be treated as claims to verify rather than conclusions to adopt.[3][5]
- Source coverage: Which courts, jurisdictions, statutes, regulations, administrative materials, and secondary sources are included, and how often are they updated?
- Citation normalization: Does the system resolve parallel reporters, short forms, docket numbers, slip opinions, and citation variants to the same authority record?
- Chunking: Does the system preserve opinion structure, including majority, concurrence, dissent, footnotes, quoted material, and procedural posture?
- Retrieval: Does it use hybrid retrieval, and can it explain whether a passage was returned because of semantic similarity, exact terms, filters, or citation signals?
- Reranking: Does it rank controlling, on-point passages above broadly similar background material?
- Verification: Can every material proposition in the generated answer be mapped to a source passage?
- Treatment checking: Does a separate validity layer identify overruling, abrogation, negative treatment, supersession, and jurisdiction-specific limitations?
- Evaluation: What benchmark tasks, dates, tool versions, and failure categories support the vendor’s accuracy claims?
Professional responsibility discussions around RAG tend to land in the same place: lawyers remain responsible for supervision, competence, and verification when they use AI tools in practice.[7] That does not mean legal RAG is useless. It means the tool has to be evaluated as part of a research workflow, not as a substitute for one. A firm that wants an operational verification protocol can pair this pipeline view with a downstream AI legal research hallucination verification protocol.
The Bottom Line for Fileable Work
RAG improves the research posture of a language model by making it fetch materials before answering. In legal research, that is a necessary improvement over a bare model inventing authority from statistical memory. It is not enough.
The stages that matter most are the ones least visible in a smooth demo: citation normalization, structure-aware chunking, hybrid retrieval, careful reranking, claim-level grounding, and a separate authority-treatment graph. If those layers are weak, the answer may contain real citations and still require substantial cleanup by the associate, paralegal, or staff attorney who inherits it after everyone else has admired the speed.
The better evaluation question is not “does this tool use RAG?” It is “can this tool show, claim by claim, what it retrieved, why it retrieved it, whether the cited text supports the proposition, and whether the authority remains usable for that proposition today?”
References
- Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools, Journal of Empirical Legal Studies, 2025.
- Retrieval-augmented generation (RAG): towards a promising LLM architecture for legal work?, Harvard Journal of Law & Technology.
- Intro to retrieval-augmented generation (RAG) in legal tech, Thomson Reuters.
- Contextual Legal RAG, TrueLaw AI.
- How AI Legal Research Works: RAG, Grounding, and Citations, Vaquill AI.
- What the Science Says About Hallucinations in Legal Research, AI Law Librarians, February 19, 2026.
- AI and You: The Critical Role of Retrieval Augmented Generation (RAG) in Legal Practice, American Bar Association, July 2024.
Comments
Join the discussion with an anonymous comment.