Why Workflow Matters More Than Tool Choice
The legal profession in 2026 faces a paradox that should concern every managing partner and ethics counsel: individual adoption of AI tools has reached between 69% (8am 2026 Legal Industry Report) and 79% (Clio Legal Trends), yet only 9% of firms have an enforced written AI policy. This gap — call it the governance deficit — means that the majority of attorneys using AI for legal research are doing so without institutional guardrails, consistent protocols, or any mechanism for accountability.
The instinct to focus on tool selection is understandable. A partner evaluating Westlaw Precision AI against Lexis+ with Protégé or Harvey is asking a reasonable question: which one is more accurate? But accuracy benchmarks alone cannot solve the governance problem. The Stanford RegLab study published in May 2024 found that legal-specific AI tools hallucinate between 17% and 34% of the time on open-ended legal queries — and those were the tools purpose-built for legal research. A general-purpose model like ChatGPT or Claude carries even higher risk, with no built-in citation grounding at all.
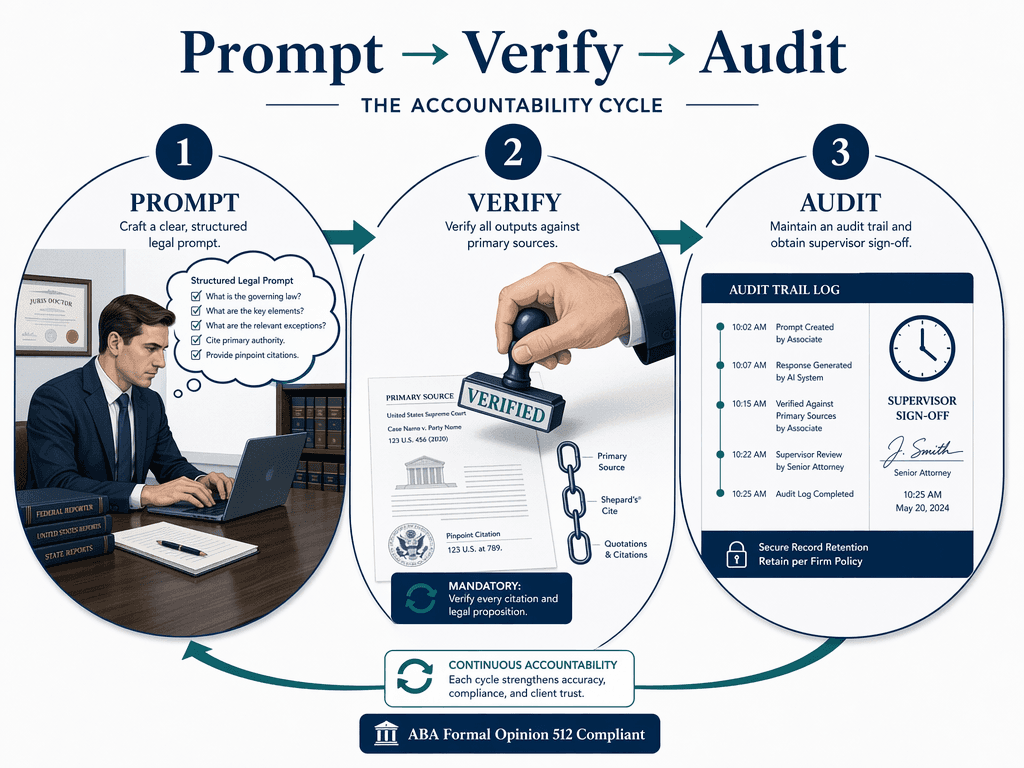
The core argument of this guide is straightforward: effective AI legal research in 2026 requires a structured workflow that sequences five distinct stages — prompt engineering, multi-source retrieval, citation verification, synthesis and drafting, and supervisor review — all governed by a traffic-light permission policy and a Prompt → Verify → Audit accountability loop derived from ABA Formal Opinion 512 and state bar guidance. Tool selection is one variable in that system, not the system itself.

Stage 1: Issue Framing and Prompt Design
The quality of an AI legal research output is bounded by the quality of the input prompt. This is not a trivial observation — it is a structural constraint of large language models. A vague or underspecified prompt will produce a plausible-sounding but legally useless answer. A well-structured prompt, by contrast, constrains the model's output space and increases the likelihood of retrieving relevant, citable material.
Effective legal prompts share several structural features. They specify jurisdiction explicitly. They request citation format (e.g., "provide full Bluebook citations"). They define the type of authority sought (statute, case law, regulation, secondary source). And they set boundaries on the temporal scope of the research. A prompt that asks "What is the standard for summary judgment in the Ninth Circuit?" will produce a materially different — and more useful — result than "Tell me about summary judgment."
The table below provides example prompts for common legal research tasks, structured to maximize output quality while minimizing hallucination risk.
| Research Task | Weak Prompt | Structured Prompt |
|---|---|---|
| Statutory interpretation | What does the ADA say about reasonable accommodation? | Provide the text of 42 U.S.C. § 12111(9) and list all Ninth Circuit decisions from 2020–2025 interpreting 'reasonable accommodation' in the context of remote work. Include full Bluebook citations. |
| Case law search | Find cases about qualified immunity | Identify all published decisions from the U.S. Court of Appeals for the Fifth Circuit between January 2022 and June 2026 that apply the qualified immunity standard from Pearson v. Callahan (2009). Provide the holding, procedural posture, and citation for each. |
| Regulatory compliance | What are the EU AI Act requirements? | List the compliance obligations for high-risk AI systems under the EU AI Act, Article 6 and Annex III, that take effect on August 2, 2026. Cite the specific article and paragraph numbers. |
| Multi-jurisdictional survey | Compare state AI disclosure rules | Identify all state bar ethics opinions issued between January 2024 and June 2026 that address attorney disclosure obligations when using generative AI. For each opinion, provide the jurisdiction, effective date, and a one-paragraph summary of the disclosure requirement. |
Stage 2: Multi-Source Retrieval Across Approved Tools
Once the research question is framed, the next stage is retrieval — sending that query to one or more AI-powered legal research tools and collecting the results. The key decision at this stage is which tool to use for which type of query, and whether to use multiple tools for the same question.
The legal AI tool market in 2026 offers several purpose-built options, each with different strengths and limitations. Westlaw Precision AI and Lexis+ with Protégé are the dominant incumbents, both built on proprietary legal databases with retrieval-augmented generation (RAG) architectures designed to ground outputs in their own corpora. CoCounsel (Thomson Reuters) offers a broader assistant interface. Harvey and vLex Vincent represent the newer generation of legal AI platforms, with Harvey focusing on large law firm workflows and vLex Vincent emphasizing international and comparative law research.
The Stanford RegLab study provides the only independent benchmark comparing these tools head-to-head on legal research accuracy. The results are sobering: Lexis+ AI (now Lexis+ with Protégé) and Ask Practical Law AI produced incorrect information more than 17% of the time, while Westlaw's AI-Assisted Research hallucinated more than 34% of the time on the same set of over 200 open-ended legal queries. These figures should not be read as a ranking — they are a warning that no single tool is reliable enough to trust without verification.
The practical implication is that multi-source retrieval is not optional. For any research question where the answer will be used in a filing, an advice memo, or a client communication, the attorney should run the same query through at least two tools and compare the results. Discrepancies between outputs are a signal to dig deeper into primary sources, not a reason to pick the more confident-sounding answer.
| Tool | Best For | Key Limitation |
|---|---|---|
| Westlaw Precision AI | U.S. federal and state case law, statutes, and regulations; strong on citation grounding within Westlaw's database | 34%+ hallucination rate on open-ended queries (Stanford RegLab 2024); limited international coverage |
| Lexis+ with Protégé | U.S. case law, statutes, and administrative materials; integrated Shepard's citation verification | 17%+ hallucination rate on open-ended queries (Stanford RegLab 2024); less effective on multi-jurisdictional surveys |
| CoCounsel (Thomson Reuters) | Broad legal research assistant tasks; document analysis and deposition preparation | Less specialized for deep statutory or regulatory research; accuracy varies by task type |
| Harvey | Large law firm workflows; complex transactional and litigation research; strong on international law | Enterprise pricing limits accessibility for small firms; less independent benchmark data available |
| vLex Vincent | International and comparative law research; multi-jurisdictional statutory analysis | Smaller U.S. case law corpus than Westlaw or Lexis; less established in U.S. litigation workflows |
For a deeper analysis of how legal-specific tools compare to general-purpose models on accuracy benchmarks, see our comparison guide on purpose-built legal AI vs. general models.
Stage 3: Citation Verification Against Primary Law
This is the non-negotiable stage of any AI legal research workflow. Every citation generated by an AI tool must be verified against the primary source before it is used in any legal document. The stakes are not theoretical: the sanctions trajectory for unverified AI-generated citations has escalated from $5,000 in Mata v. Avianca (2023) to $110,000 in Couvrette v. Wisnovsky (D. Or. 2025). Courts are no longer issuing warnings — they are imposing financial penalties that directly affect both the attorney and the firm.
The verification protocol should be systematic and documented. Every citation from an AI tool should be checked against the original source in the tool's native database (Westlaw, Lexis, or the relevant jurisdiction's official reporter). The verification should confirm four things: (1) the case or statute actually exists, (2) the holding or language attributed to it is accurate, (3) the citation format is correct, and (4) the authority has not been overruled, reversed, or superseded.
- Pull the cited case or statute in the native legal database (Westlaw, Lexis, or official reporter).
- Read the relevant holding or language in context — do not rely on headnotes or AI summaries.
- Verify the citation format against the current edition of The Bluebook or applicable court rules.
- Check the subsequent history: has the case been overruled, reversed, or criticized? Has the statute been amended or repealed?
- Document the verification in the research record, including the date and the tool used.
The verification stage is also where the attorney's professional judgment is most critical. AI tools can produce citations that are technically correct — the case exists, the citation is accurate — but the holding is misstated or taken out of context. The Stanford RegLab study documented exactly this failure mode: AI tools reciting the overruled 'undue burden' standard for abortion restrictions post-Dobbs, and misgrounded citations where the source does not actually support the claim attributed to it. Verification is not just about checking whether the citation string is real; it is about reading the source and confirming that the AI's characterization of the law is accurate.
For a comprehensive analysis of the sanctions case law and the verification discipline required, see our risk digest on AI hallucinations and the sanctions trajectory.
Stage 4: Synthesis and Drafting
With verified citations in hand, the attorney moves to the synthesis and drafting stage. This is where the AI tool shifts from being a research assistant to a drafting assistant — and where the attorney's role shifts from verifier to editor and legal strategist.
AI tools are increasingly capable of generating first-draft legal arguments, memos, and brief sections based on the verified research inputs. But the attorney's job at this stage is not to accept the AI's synthesis — it is to evaluate it critically. AI models are pattern-matching engines, not legal reasoners. They can identify relevant cases and statutes, but they cannot weigh competing authorities, distinguish unfavorable precedent, or exercise the professional judgment required to construct a persuasive legal argument.
The table below distinguishes tasks that are appropriate for AI drafting assistance from tasks that require the attorney's independent legal reasoning.
| Task Type | AI Appropriate? | Rationale |
|---|---|---|
| First-draft statement of facts (from verified sources) | Yes, with review | AI can organize verified facts into a coherent narrative; attorney must ensure accuracy and strategic framing. |
| Summary of a case holding (from verified citation) | Yes, with verification | AI can summarize; attorney must confirm the summary accurately reflects the holding and is not misleading. |
| Legal argument construction | No | AI cannot weigh competing authorities, distinguish cases, or exercise strategic judgment about which arguments to advance. |
| Statutory interpretation analysis | No | AI lacks the contextual understanding of legislative intent, canons of construction, and the specific facts of the case. |
| Citation formatting and table of authorities | Yes, with review | AI can format citations and generate tables; attorney must verify accuracy against court rules. |
| Persuasive writing (briefs, motions) | No | Persuasive writing requires understanding the audience (the judge, the opposing party) and tailoring the argument — AI cannot do this. |
Stage 5: Supervisor Review and Audit Trail
The final stage of the workflow is supervisor review and audit trail creation. This stage serves two purposes: quality control and ethics compliance. The supervisor — typically a partner, senior associate, or supervising attorney — must review the AI-generated research and drafting outputs before they are used in any client-facing document or court filing.
The supervisor's review should focus on three areas: (1) whether the research is complete and accurate, (2) whether the legal analysis is sound and appropriately distinguishes unfavorable authority, and (3) whether the AI tool was used appropriately and the verification protocol was followed. This is not a rubber-stamp review — it is a substantive check that the AI workflow produced a result that meets the firm's quality standards.
Equally important is the audit trail. Every AI-assisted research session should be documented in a manner that allows the firm to demonstrate compliance with ethics rules if challenged. The audit trail should include: the date and time of the research session, the AI tool(s) used, the prompts submitted, the outputs received, the verification steps performed (including the date each citation was verified), and the name of the attorney who performed the verification and the supervisor who reviewed the final output.
- Document the AI tool(s) used, including version and model information where available.
- Save the prompts and outputs (screenshots or exported text) in the matter file.
- Record the date and time of each verification step, and the attorney who performed it.
- Note any discrepancies between AI outputs and primary sources, and how they were resolved.
- Obtain supervisor sign-off on the final research product before it is used in any filing or client communication.
The Traffic-Light Governance Model
A structured workflow is necessary but not sufficient for ethical AI use. Firms also need a governance model that clearly defines which tasks are permitted, which require review, and which are prohibited. The traffic-light model — adapted from frameworks developed by the North Carolina Bar Association and Casemark — provides a practical, intuitive structure for this governance.
The model categorizes AI use into three zones: Green (permitted with standard verification), Yellow (requires supervisor review and enhanced verification), and Red (prohibited). The categories are not static — they should be reviewed quarterly and updated as the technology and regulatory landscape evolve.
| Zone | Definition | Examples | Requirements |
|---|---|---|---|
| Green | Permitted with standard workflow | Summarizing verified case law; formatting citations; generating first-draft statements of fact from verified sources | Standard five-stage workflow; Prompt → Verify → Audit documentation |
| Yellow | Requires supervisor review | Drafting legal arguments based on verified research; analyzing statutory language; comparing multi-jurisdictional approaches | Enhanced verification (two-tool cross-check); supervisor sign-off; documented rationale for AI use |
| Red | Prohibited | Generating legal conclusions without human review; creating citations without verification; drafting pleadings or motions without attorney editing; using general-purpose AI for legal research | Not permitted under any circumstances; violation triggers mandatory reporting to ethics committee |

Measuring Success: ROI and Continuous Improvement
The final piece of the AI legal research workflow is measurement. Without data on whether the workflow is actually improving outcomes, firms cannot make informed decisions about tool selection, policy updates, or training investments. Yet the Thomson Reuters 2026 AI in Professional Services Report found that only 18% of organizations collect any metrics on AI return on investment.
For small-to-mid-sized firms, formal ROI measurement may not be feasible. But practical proxies can provide meaningful insight into whether the AI workflow is working. The following metrics are relatively easy to track and directly relevant to the quality and efficiency of legal research.
- Time saved per research task: Compare the time required to complete a standard research task before and after implementing the AI workflow. A reduction of 30–50% is a reasonable target based on vendor claims, but firms should measure their own baseline.
- Citation error rate: Track the number of AI-generated citations that require correction during the verification stage. A high error rate (above 10%) may indicate that the tool or prompt design needs adjustment.
- Supervisor review time: If supervisor review is taking longer than the time saved in the research stage, the workflow may need to be redesigned.
- User satisfaction: Survey attorneys and paralegals on whether the AI workflow improves their research quality and reduces frustration. Qualitative feedback is valuable even without quantitative data.
- Policy compliance rate: Track the percentage of AI research sessions that follow the documented workflow. A low compliance rate indicates that the workflow is either too burdensome or not well understood.
The workflow and governance model should be reviewed quarterly. The legal AI market is evolving rapidly — new tools are released, existing tools are updated, and regulatory guidance continues to develop. A workflow that was appropriate in Q1 2026 may be outdated by Q3. The quarterly review should assess whether the traffic-light categories remain appropriate, whether the tool selection still reflects the best available options, and whether the verification protocol is keeping pace with documented hallucination rates.
Building an AI legal research workflow is not a one-time project — it is an ongoing process of design, implementation, measurement, and refinement. The firms that invest in this process now will be the ones that can confidently answer the question that every ethics committee and every court is asking: 'How did you ensure the accuracy of your AI-assisted research?' The answer should not be 'We trust the tool.' It should be 'We have a workflow.'
Comments
Join the discussion with an anonymous comment.