Why AI Literacy Is a Professional Responsibility in 2026
By mid-2026, the question is no longer whether artificial intelligence will affect legal practice. The data is in: 69% of legal professionals now personally use generative AI tools for work-related tasks, according to the 8am 2026 Legal Industry Report, which surveyed more than 1,300 legal professionals between September and October 2025. That figure has more than doubled from 31% in the prior year. Meanwhile, the American Bar Association’s 2025 survey found that 79% of legal professionals use AI tools in some capacity, though only 21% report firm-wide adoption of generative AI.
This gap between individual experimentation and institutional governance is not sustainable. The ABA’s Formal Opinion 512, issued in July 2024, made clear that a lawyer’s duty of competence under Model Rule 1.1 includes understanding the benefits and risks of the technologies they use. A lawyer who deploys a tool without understanding how it works — or what it can get wrong — is not merely taking a technical risk; they are potentially violating an ethical obligation.
This primer is designed for that reality. It maps the technical concepts behind legal AI tools — from large language models to retrieval-augmented generation — directly onto the practice contexts, risk profiles, and professional responsibility duties that matter to attorneys, paralegals, legal operations leaders, compliance officers, and in-house counsel. Each term is defined, illustrated with a legal application, linked to a specific ethics consideration, and supported by current adoption data. The goal is not to make every reader a machine learning engineer. It is to provide the baseline literacy that Model Rule 1.1 now requires.

Core AI Concepts Every Legal Professional Must Know
The following terms form the foundation of AI literacy for legal practice. Each entry includes a plain-language definition, a concrete legal application, a risk or ethics note tied to professional responsibility rules, and a current data point where available.
Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning
Artificial intelligence is the broad field of computer systems designed to perform tasks that normally require human intelligence. Machine learning is a subset of AI in which systems learn patterns from data without being explicitly programmed for every rule. Deep learning is a further subset that uses multi-layered neural networks to recognize complex patterns — the technology behind most modern language models.
Legal application: Predictive coding in e-discovery uses machine learning trained on human-reviewed document samples to classify millions of additional documents as relevant or not relevant. This was the first major AI application in legal practice, introduced around 2010.
Risk note: ML models are only as good as their training data. Biased or incomplete datasets can produce systematically skewed results — a concern that directly implicates a lawyer’s duty to supervise and verify the output of any tool used in client representation.
Generative AI vs. Extractive AI
Extractive AI identifies and pulls existing data points from a source — for example, finding all dates in a contract. Generative AI creates new content — text, images, or code — based on patterns learned from training data. Most legal AI tools now combine both approaches.
Legal application: An extractive model can flag every indemnification clause in a 200-page merger agreement. A generative model can draft a first-pass summary of those clauses. The distinction matters because extractive outputs are generally more verifiable, while generative outputs require careful human review for accuracy.
Large Language Models (LLMs) and Small Language Models (SLMs)
An LLM is a type of generative AI trained on vast text corpora — billions or trillions of words — to predict and generate human-like text. GPT-4 and Claude are examples. An SLM is a smaller, more specialized model trained on a narrower dataset. SLMs run faster, cost less to operate, and are easier to customize for niche legal tasks.
Legal application: A firm might use a general-purpose LLM for broad legal research and a fine-tuned SLM for a specific recurring task, such as extracting key terms from residential lease agreements. The SLM will be faster and less prone to off-topic errors, but it will lack the breadth of knowledge of the larger model.
Risk note: LLMs work by predicting the next most probable word in a sequence. They do not “know” facts in the human sense. This probabilistic architecture is the root cause of hallucination — the generation of confident-sounding but factually incorrect output.
Natural Language Processing (NLP)
NLP is the branch of AI that enables computers to understand, interpret, and generate human language. It is the underlying technology that powers everything from semantic search in legal research platforms to clause extraction in contract analysis tools.
Legal application: Modern legal research platforms use NLP to understand the meaning behind a query, not just match keywords. A search for “duty of care in premises liability” returns cases about that concept even if the exact phrase does not appear. This is a significant advance over Boolean search, but it also means the system’s interpretation of your query may differ from your intent.
Advanced AI Architectures in Legal Practice
Beyond the foundational concepts, several specific architectures are reshaping how legal work gets done. Understanding these is critical because they determine what a tool can and cannot do, and where the human-in-the-loop must remain.
Retrieval-Augmented Generation (RAG)
RAG is an architecture that combines a generative LLM with a real-time retrieval system. Before the model generates a response, it searches a specified set of documents — a firm’s contract database, a curated legal library, or a set of court filings — and uses the retrieved content as context for its answer. This grounds the output in authoritative sources rather than relying solely on the model’s training data.
Legal application: A RAG-powered legal research tool retrieves relevant statutes and case law from a verified database before generating a summary, rather than inventing citations from its training data. This dramatically reduces — though does not eliminate — the risk of hallucinated authorities.
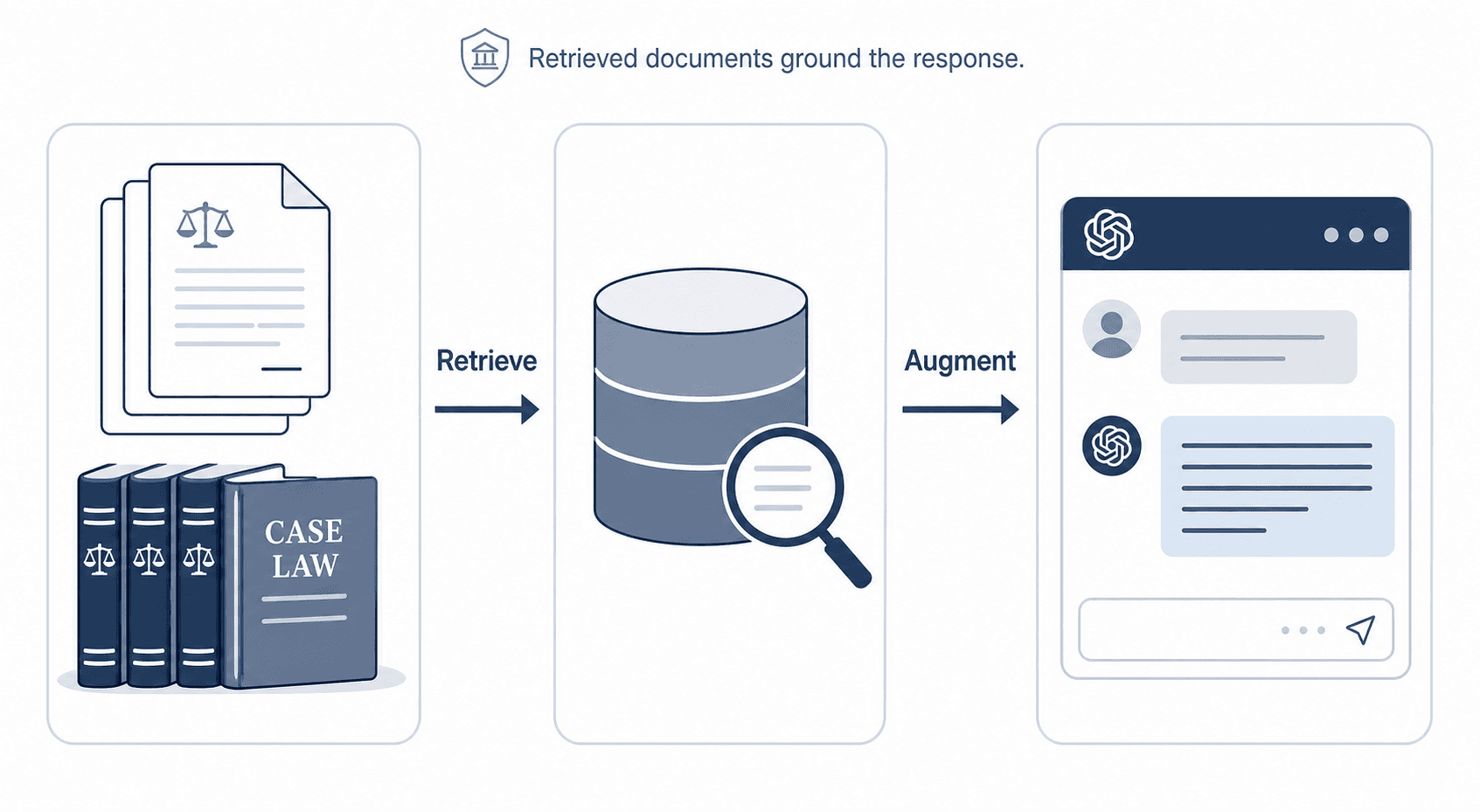
For a step-by-step guide on building a RAG-based legal research workflow, see our AI Legal Research Workflow Guide.
Agentic AI
Agentic AI refers to systems that can plan, reason, and execute multi-step processes with minimal human intervention. Unlike a standard generative AI that responds to a single prompt, an agentic system can break down a complex task, execute sub-steps in sequence, use external tools, and adapt its approach based on intermediate results.
Legal application: An agentic AI in a law firm could review incoming invoices, check them against the client’s billing guidelines, flag discrepancies, identify potential conflicts of interest, and prepare a summary for partner review — all without being prompted at each step.
Fine-Tuning
Fine-tuning takes a pre-trained LLM and adjusts its parameters using a specialized dataset — for example, thousands of annotated contract clauses or a library of briefs from a specific practice area. This produces a model that performs better on the target task than the general-purpose version.
Legal application: A firm specializing in intellectual property litigation could fine-tune a model on its own prior filings, relevant patent law decisions, and USPTO procedural rules. The resulting model would generate more accurate first drafts of IP-specific motions than a general-purpose LLM.
Risk note: Fine-tuning requires high-quality, representative training data. If the dataset contains errors, biases, or outdated law, the fine-tuned model will amplify those flaws. Additionally, fine-tuning does not eliminate hallucination — it shifts the model’s knowledge base but does not change its probabilistic architecture.
Technology-Assisted Review (TAR) / Predictive Coding
TAR, also called predictive coding, was the first major AI application in legal practice, introduced around 2010. It uses machine learning trained on human-reviewed document samples to classify large document sets as relevant or not relevant to a discovery request. The model learns from attorney coding decisions and applies that learning across millions of documents.
Legal application: In a complex commercial litigation matter involving 5 million documents, a TAR system can reduce the review set to a fraction of that size after an attorney reviews a few thousand representative documents. Courts have generally accepted TAR as a valid review methodology when properly validated.
Risk note: TAR requires transparent validation. The producing party must be able to demonstrate that the model achieved acceptable recall and precision levels. A poorly trained TAR model can miss critical documents or over-produce irrelevant material, both of which carry professional responsibility implications.
Hallucination: The Defining Risk for Legal AI
Hallucination is the term for when an AI model produces factually incorrect or completely fabricated information while appearing confident and authoritative. In a legal context, this most commonly manifests as invented case citations, misstated statutes, or fabricated factual assertions in drafted documents.
Why it happens: LLMs do not retrieve facts from a database. They predict the most statistically probable sequence of words based on their training data. When the model encounters a gap in its knowledge, it fills that gap with plausible-sounding text — not with an honest “I don’t know.” This is a feature of the architecture, not a bug that can be fully eliminated.
The legal consequences are well-documented. Researcher Damien Charlotin maintains a database tracking court decisions involving AI hallucination sanctions, and the number of reported cases continues to grow. Attorneys have been sanctioned, ordered to pay opposing counsel’s fees, and referred to bar disciplinary authorities for submitting briefs containing AI-fabricated citations.
For a detailed analysis of documented hallucination cases, sanctions trajectories, and the verification discipline every lawyer must adopt, see our dedicated article: AI Hallucinations in Legal Practice: The Sanctions Trajectory.
Professional-Grade vs. Consumer-Grade AI: Why It Matters
Not all AI tools are built for legal work. The distinction between professional-grade and consumer-grade AI is one of the most important concepts for legal professionals to understand, because it directly affects accuracy, confidentiality, and professional responsibility.
Professional-grade AI tools are built on curated, verified legal content — statutes, case law, regulations, and treatises that have been reviewed for accuracy. They typically include RAG architectures that retrieve from these verified sources, data-handling policies designed to protect client confidentiality, and audit trails that document how the system arrived at its output.
Consumer-grade tools, including free versions of general-purpose LLMs, are trained on internet-scale data of unknown quality. They may retain user inputs for model training, creating a direct risk to attorney-client privilege under Model Rule 1.6. They do not distinguish between authoritative legal sources and random web content. And they provide no audit trail for how an answer was generated.
For a comprehensive ethics and risk framework covering consumer-grade tools, see our guide: ChatGPT for Legal Work: The Complete Ethics and Risk Framework.
Cross-Cutting Themes: Data Privacy, Bias, and Billing
Three practice-wide considerations cut across every AI tool and use case. Understanding them is essential for responsible deployment.
Data Privacy and Attorney-Client Privilege (Model Rule 1.6)
When a lawyer inputs client information into an AI tool, that data may be transmitted to and stored on the vendor’s servers. Whether this constitutes a waiver of attorney-client privilege depends on the tool’s data-handling policies, the terms of service, and the jurisdiction’s rules on third-party disclosure.
Key considerations include: whether the vendor trains its models on user inputs, whether data is encrypted in transit and at rest, whether the vendor has contractual obligations to maintain confidentiality, and whether the tool is deployed in a single-tenant or multi-tenant architecture. The 8am 2026 Legal Industry Report found that data security is the top concern for legal professionals using AI, cited by 46% of respondents, followed by ethical issues (42%) and privilege concerns (39%).
Algorithmic Bias in Legal Outcomes
AI models trained on historical legal data can inherit and amplify existing biases in the legal system. A model trained on past sentencing decisions, for example, may replicate patterns of racial disparity. A contract review tool trained on a dataset dominated by certain industries may perform poorly on contracts from other sectors.
The duty to supervise and verify AI outputs under Model Rule 1.1 includes an obligation to be aware of potential bias in the tools used. This is not a theoretical concern — biased outputs can directly harm clients and expose the lawyer to malpractice liability.
Billing Implications Under Model Rule 1.5
The ABA’s Formal Opinion 512 provides specific guidance on billing for AI-assisted work. A lawyer may charge a reasonable fee for time spent using AI to draft documents — for example, 15 minutes to input a prompt and review the output. However, a lawyer normally cannot charge the client for time spent learning how to use the AI tool itself.
This distinction has significant financial implications. McKinsey estimates that 22% of a lawyer’s job is automatable with current AI technology, and that 44% of legal tasks are technically automatable. Clio’s analysis suggests that generative AI could put $27,000 of revenue at risk for every lawyer who bills by the hour, as tasks that once took hours are compressed into minutes.
Quick-Reference Adoption Statistics Table
The following table consolidates key adoption, training, and impact statistics from multiple 2025-2026 surveys. Each figure is attributed to its specific source, and readers should note that different surveys measure different constructs (e.g., “any AI tool use” vs. “generative AI for work”).
| Statistic | Figure | Source | Year |
|---|---|---|---|
| Legal professionals personally using GenAI at work | 69% | 8am Legal Industry Report (n=1,300+) | 2026 |
| Legal professionals using AI tools in any capacity | 79% | Clio Legal Trends Report | 2025 |
| Firm-wide GenAI adoption | 21% | ABA Survey | 2025 |
| Corporate legal departments that have adopted AI | 52% | ACC/Everlaw Survey | 2025 |
| In-house teams expecting to depend less on outside counsel due to AI | 64% | ACC/Everlaw Survey | 2025 |
| Firms providing no AI training | 54% | 8am Legal Industry Report | 2026 |
| Lawyers who say AI saves them time each week | 61% | 8am Legal Industry Report | 2026 |
| Legal professionals who are optimistic about AI’s long-term impact | 54% | 8am Legal Industry Report | 2026 |
| Legal professionals who believe AI could narrow the access-to-justice gap | 76% | 8am Legal Industry Report | 2026 |
| Percentage of a lawyer’s job automatable today | 22% | McKinsey | 2025 |
| AmLaw 100 firms anticipating attorney headcount reduction | 0% | Harvard Law School CLP | 2025 |
Ethics Compliance Checklist for AI Tool Use
The following checklist is derived from ABA Formal Opinion 512 and the Model Rules of Professional Conduct. It is not legal advice and does not substitute for jurisdiction-specific guidance. It is a starting point for any legal professional evaluating or deploying an AI tool.
- Competence assessment (Model Rule 1.1). Have you read the vendor’s documentation and do you understand how the tool generates its outputs? Can you explain its limitations — including hallucination risk — to a client or a court? Have you verified that you or your team have the technical literacy to supervise the tool’s work?
- Confidentiality verification (Model Rule 1.6). Have you reviewed the vendor’s data-handling policy? Does the vendor train its models on user inputs? Is data encrypted in transit and at rest? Does the tool use a single-tenant or multi-tenant architecture? Have you obtained client consent if required by your jurisdiction?
- Client communication (Model Rule 1.4). Have you informed the client that you are using AI tools in their matter? Does your engagement letter address AI use? Have you discussed the benefits and risks at a level the client can understand?
- Fee transparency (Model Rule 1.5). Are you billing only for time actually spent using the tool (prompting, reviewing, editing), not for time spent learning it? Is your billing description accurate and not misleading? Have you adjusted your billing practices to reflect the reduced time AI enables?
- Output verification. Have you independently verified every citation, factual assertion, and legal conclusion generated by the tool against primary sources? Do you have a documented verification process? Is there a second-review step for high-stakes work product?
- Ongoing monitoring. Have you set a calendar reminder to review the tool’s capabilities and data policies at least quarterly? Are you monitoring for new ethics opinions, court rules, or regulatory guidance in your jurisdiction? Have you subscribed to a reliable update source for legal AI regulation?
- Firm-wide policy. If you are in a leadership role, does your firm have a written AI use policy? Does it address tool approval, data security, training requirements, and consequences for misuse? 53% of firms currently have no AI policy or are unaware of one (ABA 2025).
For practical guidance on integrating AI into your daily workflows, see our AI in Law Practice Workflow Integration Guide and our AI Legal Document Workflow Guide.
Comments
Join the discussion with an anonymous comment.